DeepSeek横空出世后,犹如蝴蝶效应迅速在全球范围内引发轰动,甚至“从华盛顿到华尔街再到硅谷都感受到了震动”。在这背后,DeepSeek其实并非颠覆性的创新,而是大多基于业界已有技术成果,将降低推理等技术成本和兼顾实现高性能水准进行了良好结合。这使得国际科技巨头的“砸钱”策略遭遇前所未有的质疑,但其仍将继续大规模投入AI设施。
目前,全球科技巨头乃至世界各地掀起的数据中心热潮,是以采购不计其数的英伟达AI芯片作为运行支撑。但一方面,若DeepSeek证明不依赖于价格高昂的芯片投入也能训练出强大AI模型,那么英伟达股价及增长面临进一步回调的压力。另一方面,正如“杰文斯悖论”带来的影响,尽管训练成本的下降可能会暂时减少对GPU的需求,但大模型变得更加经济且效率提高,将推动更多企业加入到使用模型的行列,进而将增加对于芯片的需求。
掀起大模型“性能-成本”革命
随着全球人工智能竞争日趋激烈,DeepSeek的出现被较广泛视为一场“冲击波”。
据复旦中美友好互信合作计划作者姚旭、邱砺撰文称,DeepSeek形成了“技术-市场-政治”共振现象引发三重冲击波:技术路线上,其“效率优先”范式使得美国科技界重新评估Scaling Law是否还依然奏效——OpenAI在2020年提出的Scaling Law是现今算力“军备竞赛”的基础。在资本市场中,包括英伟达在内的算力、电力股票暴跌,OpenAI估值模型遭摩根士丹利下调23%。在美国政策反应层面,DeepSeek的崛起冲击了美国政府对华芯片和人工智能限制政策,带来一系列监管政策上的连锁反应。
而形成这场冲击波的关键在于,中国AI初创公司深度求索(DeepSeek)在短短一个月内相继推出DeepSeek-V3和DeepSeek-R1两款大模型。2024年12月26日,其发布的开源模型DeepSeek-V3首次实现万亿参数下的轻量化部署。2025年1月20日,开源模型DeepSeek-R1通过动态专家系统架构,在保持千亿参数规模下将推理效率提升至行业标杆的3.2倍,同时以低至1/10的训练成本实现了与顶尖产品相媲美的性能。

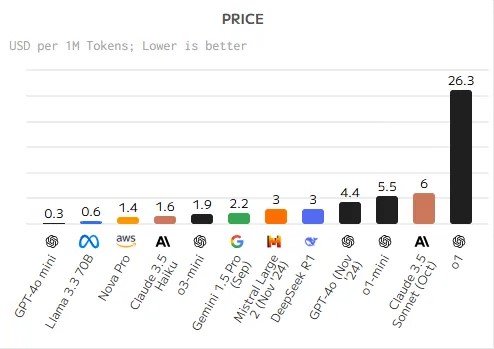
(根据Artificial Analysis排名,Deepseek在AI质量上排名第三,但其训练成本是目前最强AI大模型O1的九分之一。)
根据DeepSeek技术报告,DeepSeek-V3模型的训练成本为557.6万美元,使用的是算力受限的英伟达H800 GPU集群。相比之下,Meta旗下Llama-3.1模型的训练成本超过6000万美元,而OpenAI的GPT-4o模型的训练成本为1亿美元,且使用的是性能更加优异的英伟达H100 GPU集群。此外,DeepSeek给出反馈的时长也大部分控制在5秒至35秒之间,通过算法轻量化、计算效率最大化、资源利用率优化,成功压缩了计算时间周期。
在复旦大学计算机学院副教授郑骁庆看来,DeepSeek在工程优化方面取得了显著成果,特别是在降低训练和推理成本方面,但其中大多是基于业界已有的技术探索。比如键值缓存(Key-Value cache)管理对缓存数据进行压缩,另一个是混合专家模型(MoE),指在推理时只需使用模型的某个特定模块,而不需要所有模型的网络结构和参数都参与推理过程。此外,Deepseek还采用了FP8混合精度训练的技术手段。DeepSeek的创新之处就在于,很好地将这些能够降低技术和推理成本的技术整合起来,而非颠覆性的创新。
另有行业分析指出,在算力有限的背景下,DeepSeek实现了技术架构、数据策略、工程实践等关键突破,在超越ChatGPT、谷歌Gemini等全球顶尖科技巨头研发的模型产品同时,也击穿了行业三大定式,即打破“越强越贵”的成本魔咒,超越“性能-成本-速度”的不可能三角和走出“参数膨胀”陷阱。这将促使全球科技界重新思考AI大模型发展路径。
导致硅谷“烧钱”模式遭广泛质疑
在DeepSeek-R1模型引发的震荡中,美国科技股已经大跌,英伟达、Meta、谷歌和亚马逊的股价几乎无一例外地立即遭到砸盘。例如AI投资机构Menlo Ventures负责人Deedy对比谷歌Gemini和DeepSeek-R1后表示,DeepSeek-R1更便宜、上下文更长、推理性能更佳。低成本比肩o1模型,令硅谷的“烧钱”模式一时间遭到广泛质疑。
据瑞银(UBS)数据,去年美国大型科技公司在人工智能方面的投资达到2240亿美元,预计到2025年将达到2800亿美元,很大一部分将投入流向数据中心基础设施的建设。其中,Meta计划2025年资本投入600-650亿美元,用于推动人工智能战略;微软承诺今年投入800亿美元用于AI基础设施;谷歌预计2025年将在资本支出方面投入750亿美元,同比激增逾42.7%;亚马逊计划将今年的资本支出增加至1000亿美元,大幅提升20.5%。
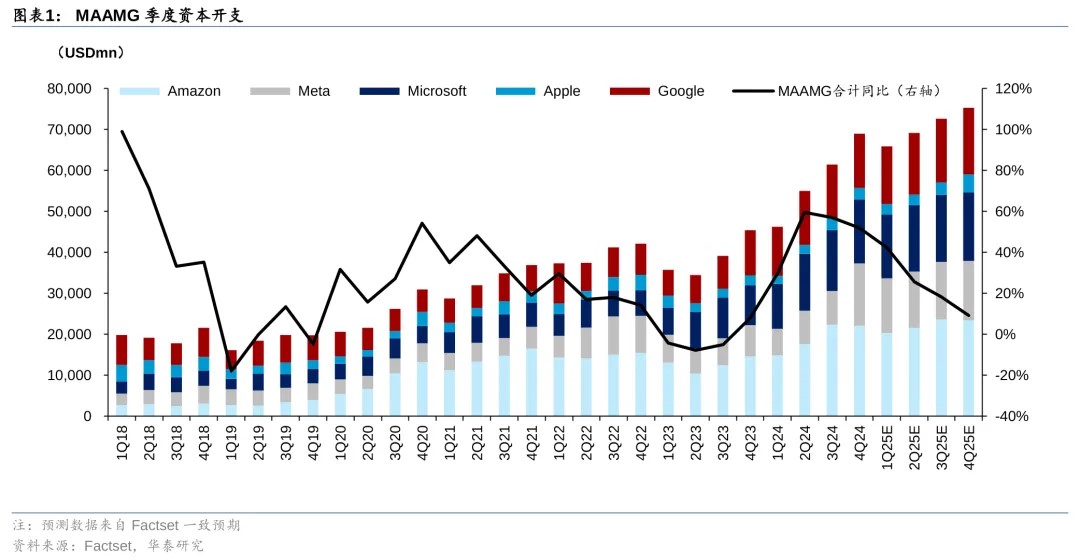
Futurum Group分析师Daniel Newman表示,“考虑到这些巨额开支,他们急需提高AI的收入回报,但当前发生的事情(DeepSeek)对美国而言是一个警钟… 目前,人工智能的资本支出实在太多,但消费却不足。”Lightning AI首席执行官William Falcon则称,如果DeepSeek模型被证明非常强大(看起来确实如此),而且价格非常便宜,那么未来很多公司将不再大规模使用OpenAI。而这一新进展“也使所有这些公司的估值受到质疑”。
通过显著提高数据质量和改进模型结构,DeepSeek展示了与众不同的高效训练途径,表明前沿AI能为可能不需要大量计算资源就能实现。摩根士丹利认为,“更大(的模型)不再等于更聪明”,通过巧妙的工程设计和高效的训练方法,高效利用资源可能比纯粹的计算能力更重要。这将激发一波创新浪潮,并促使各企业探索具有成本效益的AI开发和部署方法。
显然,在DeepSeek发布后,业界已把针对大模型计算成本的讨论上升为“关键话题”。
尽管质疑声开始此起彼伏,但美国科技巨头均表示将继续大规模投入AI设施。其中,META CEO扎克伯格表示,他仍然相信大力投资公司的人工智能基础设施会成为战略优势,现在就对基础设施和资本支出的走势做出判断可能还为时过早。微软CEO萨蒂亚·纳德拉则认为,增加AI支出将有助于缓解限制公司充分利用人工智能的能力的产能问题。随着人工智能变得更加高效和广泛可用,“我们将看到需求呈指数级增长。”此外,美国政府宣布投入5000亿美元的“星际之门”AI基础设施项目,也重申了对先进芯片需求的认可。
总体上,硅谷、华盛顿、华尔街等地因中国人工智能公司DeepSeek的意外崛起而陷入不同程度混乱。许多分析师认为DeepSeek的成功动摇了推动美国人工智能行业发展的核心信念,但也有不凡反驳称,许多担忧都是夸大其词。尽管DeepSeek代表人工智能效率的真正进步,但美国AI行业仍然具有关键优势,而且数据中心等基础设施建设仍然迫切。
创新与效益或将增加芯片需求
众所周知,全球科技巨头乃至世界各地正掀起一场数据中心基建热潮,由此采购了英伟达不计其数的GPU芯片。但市场若对“高算力=高成本”的逻辑产生质疑,包括不依赖于价格高昂的芯片投入也能训练出强大AI模型,那么英伟达股价及增长难逃进一步回调的压力。
“过去算力决定AI发展似乎没有争议,但现在有一种观点认为,DeepSeek揭露了AI的能力可能与算力多少并不完全直接关联。”Gartner分析师盛陵海表示,如果这一结论坐实,那就不需要那么多用于AI训练的加速卡了,英伟达的市场想象空间也会大幅缩水。
行业人士进一步称,短期内DeepSeek的技术突破直接冲击了英伟达的股价和垄断地位,但中长期双方可能形成“技术突破→应用扩展→算力反哺”的动态平衡,对英伟达的长远影响主要体现在对硬件需求、软件生态的推动以及可能的竞争压力上。英伟达需加速技术创新并调整市场策略,而DeepSeek的持续发展将深度影响全球AI产业价值链分配。

不过,郑骁庆指出,DeepSeek的低成本大效能创新,并不会对英伟达的芯片采购量或出货量产生太大的影响。因为在寻找有效的整合解决方案时,需要进行大量的前期研究与消融实验。而这些测试就非常依赖于芯片,以确定哪个方案是有效的以及哪些方案的整合是有效。
此外,DeepSeek的研究表明,很多中小企业都能用得起这样的大模型。尽管训练成本的下降可能会暂时减少对GPU的需求,但大模型变得更加经济,会使原本因为模型成本太高而不打算使用大模型的企业,加入到使用模型的行列,反而会增加对于芯片的需求。
摩根大通分析师表示,DeepSeek展示的成本效益和AI创新将带来对更高性能GPU的“强劲需求”。因此,英伟达在先进AI芯片领域的领导地位“应该能够让他们解锁新的用例”,同时博通、Marvell和美光等其他芯片公司也将在这一创新热潮中受益。恰如“杰文斯悖论”带来的影响,摩根大通预计,成本效率的提高“应该会加速”人工智能的开发和应用,从而带来更多消费,亚马逊、Alphabet和Meta等将在中期内继续加大资本支出。
另有分析称,DeepSeek的意外“攻城”并不代表英伟达的技术护城河已经瓦解,但投资者需观察其数据中心业务增速能否继续维持,尤其是季度环比增长是否还能保持强劲势头。重压之下,英伟达即将在2月26日发布的财报数据就显得格外关键,尤其是最重要的数据中心收入增幅。若这一核心引擎继续高速扩张,英伟达可能会摆脱质疑、重夺投资者青睐;若其数据中心业务出现显著放缓,则会加剧市场对“AI芯片是否已经见顶”的担忧。