
ChatGPT激发了人们的好奇心也打开了人们的想象力,伴随着生成式AI(Generative AI)以史无前例的速度被广泛采用,AI算力的需求激增。与传统计算发展路径类似,想让AI普及且发掘出AI的全部潜力,AI计算必须合理的分配在云端服务器和端侧装置(如PC,手机,汽车, IoT装置),而不是让云端承载所有的AI负荷。这种云端和端侧AI协同作战的架构被称为混合AI(Hybrid AI),将提供更强大,更有效和更优化的AI。换句话说,要让AI真正触手可及,深入日常生活中的各种场景,离不开端侧AI的落地。
端侧AI将机器学习带入每一个IoT设备,减少对云端算力的依赖,可在无网络连接或者网络拥挤的情况下,提供低延迟AI体验,还具备低功耗、高数据隐私性和个性化等显著优势。AIoT的一个最重要载体是电池驱动的超低功耗小型IoT设备,其数量庞大且应用丰富,在新一代AI的浪潮中,端侧AI是实现人工智能无处不在的关键,而为电池驱动的低功耗IoT装置赋能AI又是让端侧AI变为现实的关键。
2024年11月5日,炬芯科技股份有限公司董事长兼CEO周正宇博士受邀出席Aspencore2024全球CEO峰会,结合AI时代热潮及端侧AI所带来的新一代AI趋势,分享炬芯科技在低功耗端侧AI音频的创新技术及重磅产品,发表主题演讲:《Actions Intelligence: 端侧AI音频芯未来》。

周正宇博士表示:在从端侧AI到生成式AI的广泛应用中,不同的AI应用对算力资源需求差异显著,而许多端侧AI应用是专项应用, 并不需要大模型和大算力。尤其是以语音交互,音频处理,预测性维护,健康监测等为代表的AIoT领域。
炬芯科技目标是在电池驱动的中小模型机器学习IoT设备上实现高能效的AI算力
在便携式产品和可穿戴产品等电池驱动的IoT设备中,炬芯科技致力于在毫瓦级功耗下实现TOPS级别的AI算力,以满足IoT设备对低功耗、高能效的需求。以穿戴产品(耳机和手表)为例,平均功耗在10mW-30mW之间,存储空间在10MB以下,这框定了低功耗端侧AI,尤其是可穿戴设备的资源预算。
周正宇博士指出“Actions Intelligence”是针对电池驱动的端侧AI落地提出的战略,将聚焦于模型规模在一千万参数(10M)以下的电池驱动的低功耗音频端侧AI应用,致力于为低功耗AIoT装置打造在10mW-100mW之间的功耗下提供0.1-1TOPS的通用AI算力。也就是说“Actions Intelligence”将挑战目标10TOPS/W-100TOPS/W的AI算力能效比。根据ABI Research预测,端侧AI市场正在快速增长,预计到2028年,基于中小型模型的端侧AI设备将达到40亿台,年复合增长率为32%。到2030年,预计75%的这类AIoT设备将采用高能效比的专用硬件。
现有的通用CPU和DSP解决方案虽然有非常好的算法弹性,但是算力和能效远远达不成以上目标,依据ARM和Cadence的公开资料,同样使用28/22nm工艺,ARM A7 CPU 运行频率1.2GHz时可获取0.01TOPS的理论算力,需要耗电100mW,即理想情况下的能效比仅为0.1TOPS/W;HiFi4 DSP运行600MHz时可获取0.01TOPS的理论算力,需要耗电40mW,即理想情况下的能效比0.25TOPS/W。即便专用神经网路加速器(NPU)的IP ARM周易能效比大幅提升,但也仅为2TOPS/W。
以上传统技术的能效比较差的本质原因均源于传统的冯•诺依曼计算结构。传统的冯•诺伊曼计算系统采用存储和运算分离的架构,存在“存储墙”与“功耗墙”瓶颈,严重制约系统算力和能效的提升。
在冯•诺伊曼架构中,计算单元要先从内存中读取数据,计算完成后,再存回内存。随着半导体产业的发展和需求的差异,处理器和存储器二者之间走向了不同的工艺路线。由于工艺、封装、需求的不同,存储器数据访问速度跟不上处理器的数据处理速度,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。两者之间数据交换通路窄以及由此引发的高能耗两大难题,在存储与运算之间筑起了一道“存储墙”。
此外,在传统架构下,数据从内存单元传输到计算单元需要的功耗是计算本身的许多倍,因此真正用于计算的能耗和时间占比很低,数据在存储器与处理器之间的频繁迁移带来严重的传输功耗问题,称为“功耗墙”。
基于SRAM的存内计算是目前低功耗端侧AI的最佳解决方案
周正宇博士表示:弱化或消除“存储墙”及“功耗墙”问题的方法是采用存内计算Computing-in-Memory(CIM)结构。其核心思想是将部分或全部的计算移到存储中,让存储单元具有计算能力,数据不需要单独的运算部件来完成计算,而是在存储单元中完成存储和计算,消除了数据访存延迟和功耗,是一种真正意义上的存储与计算融合。同时,由于计算完全依赖于存储,因此可以开发更细粒度的并行性,大幅提升性能尤其是能效比。
机器学习的算法基础是大量的矩阵运算,适合分布式并行处理的运算,存内计算非常适用于人工智能应用。
要在存储上做计算,存储介质的选择是成本关键。单芯片为王,炬芯的目标是将低功耗端侧AI的计算能力和其他SoC的模块集成于一颗芯片中,于是使用特殊工艺的DDR RAM和Flash无法在考虑范围内。而采用标准SoC适用的CMOS工艺中的SRAM和新兴NVRAM(如RRAM或者MRAM)进入视野。SRAM工艺非常成熟,且可以伴随着先进工艺升级同步升级,读写速度快、能效比高,并可以无限多次读写。唯一缺陷是存储密度较低,但对于绝大多数端侧AI的算力需求,该缺陷不会成为阻力。短期内,SRAM是在低功耗端侧AI设备上打造高能效比的最佳技术路径,且可以快速落地,没有量产风险。
长期来看,新兴NVRAM 如RRAM由于密度高于SRAM,读功耗低,也可以集成入SoC,给存内计算架构提供了想象空间。但是RRAM工艺尚不成熟,大规模量产依然有一定风险,制程最先进只能到22nm,且存在写次数有限的致命伤(超过会永久性损坏)。故周正宇博士预期未来当RRAM技术成熟以后,SRAM 跟RRAM的混合技术有机会成为最佳技术路径,需要经常写的AI计算可以基于SRAM的CIM实现,不经常或者有限次数写的AI计算由RRAM的CIM实现,基于这种混合技术有望实现更大算力和更高的能效比。
炬芯科技创新性采用模数混合设计实现基于SRAM的存内计算(CIM)
业界公开的基于SRAM的CIM电路有两种主流的实现方法,一是在SRAM尽量近的地方用数字电路实现计算功能, 由于计算单元并未真正进入SRAM阵列,本质上这只能算是近存技术。另一种思路是在SRAM介质里面利用一些模拟器件的特性进行模拟计算,这种技术路径虽然实现了真实的CIM,但缺点也很明显。一方面模拟计算的精度有损失,一致性和可量产性完全无法保证,同一颗芯片在不同的时间不同的环境下无法确保同样的输出结果。另一方面它又必须基于ADC和DAC来完成基于模拟计算的CIM和其他数字模块之间的信息交互,整体数据流安排以及界面交互设计限制多,不容易提升运行效率。
炬芯科技创新性的采用了基于模数混合设计的电路实现CIM,在SRAM介质内用客制化的模拟设计实现数字计算电路,既实现了真正的CIM,又保证了计算精度和量产一致性。
周正宇博士认为,炬芯科技选择基于模数混合电路的SRAM存内计算(Mixed-Mode SRAM based CIM,简称MMSCIM)的技术路径,具有以下几点显著的优势:
第一,比纯数字实现的能效比更高,并几乎等同于纯模拟实现的能效比;
第二,无需ADC/DAC, 数字实现的精度,高可靠性和量产一致性,这是数字化天生的优势;
第三,易于工艺升级和不同FAB间的设计转换;
第四,容易提升速度,进行性能/功耗/面积(PPA)的优化;
第五,自适应稀疏矩阵,进一步节省功耗,提升能效比。
而对于高质量的音频处理和语音应用,MMSCIM是最佳的未来低功耗端侧AI音频技术架构。由于减少了在内存和存储之间数据传输的需求,它可以大幅降低延迟,显著提升性能,有效减少功耗和热量产生。对于要在追求极致能效比电池供电IoT设备上赋能AI,在每毫瓦下打造尽可能多的 AI 算力,炬芯科技采用的MMSCIM技术是真正实现端侧AI落地的最佳解决方案。
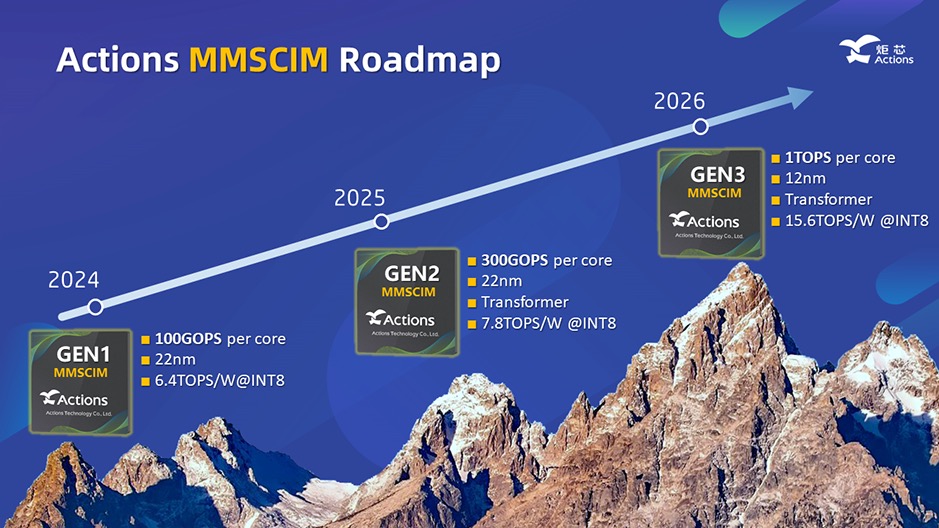
周正宇博士首次公布了炬芯科技MMSCIM路线规划,从路线图中显示:
1、炬芯第一代(GEN1)MMSCIM已经在2024年落地, GEN1 MMSCIM采用22 纳米制程,每一个核可以提供100 GOPS的算力,能效比高达6.4 TOPS/W @INT8;
2、到 2025 年,炬芯科技将推出第二代(GEN2)MMSCIM,GEN2 MMSCIM采用22 纳米制程,性能将相较第一代提高三倍,每个核提供300GOPS算力,直接支持Transformer模型,能效比也提高到7.8TOPS/W @INT8;
3、到 2026 年,推出新制程12 纳米的第三代(GEN3)MMSCIM,GEN3 MMSCIM每个核达到1 TOPS的高算力,支持Transformer,能效比进一步提升至15.6TOPS/W @INT8。
以上每一代MMSCIM技术均可以通过多核叠加的方式来提升总算力,比如MMSCIM GEN2单核是300 GOPS算力,可以通过四个核组合来达到高于1TOPS的算力。
炬芯科技正式发布新一代基于MMSCIM端侧AI音频芯片
炬芯科技成功落地了第一代MMSCIM在500MHz时实现了0.1TOPS的算力,并且达成了6.4TOPS/W的能效比,受益于其对于稀疏矩阵的自适应性,如果有合理稀疏性的模型(即一定比例参数为零时),能效比将进一步得到提升,依稀疏性的程度能效比可达成甚至超过10TOPS/W。基于此核心技术的创新,炬芯科技打造出了下一代低功耗大算力、高能效比的端侧AI音频芯片平台。
周正宇博士代表炬芯科技正式发布全新一代基于MMSCIM端侧AI音频芯片,共三个芯片系列:
第一个系列是ATS323X,面向低延迟私有无线音频领域;
第二个系列是ATS286X,面向蓝牙AI音频领域;
第三个系列是ATS362X,面向AI DSP领域。
三个系列芯片均采用了CPU(ARM)+ DSP(HiFi5)+ NPU(MMSCIM)三核异构的设计架构,炬芯的研发人员将MMSCIM和先进的HiFi5 DSP融合设计形成了炬芯科技“Actions Intelligence NPU(AI-NPU)”架构,并通过协同计算,形成一个既高弹性又高能效比的NPU架构。在这种AI-NPU架构中MMSCIM支持基础性通用AI算子,提供低功耗大算力。同时,由于AI新模型新算子的不断涌现,MMSCIM没覆盖的新兴特殊算子则由HiFi5 DSP来予以补充。
以上全部系列的端侧AI芯片,均可支持片上1百万参数以内的AI模型,且可以通过片外PSRAM扩展到支持最大8百万参数的AI模型,同时炬芯科技为AI-NPU打造了专用AI开发工具“ANDT”,该工具支持业内标准的AI开发流程如Tensorflow,HDF5,Pytorch和Onnx。同时它可自动将给定AI算法合理拆分给CIM和HiFi5 DSP去执行。ANDT是打造炬芯低功耗端侧音频AI生态的重要武器。借助炬芯ANDT工具链轻松实现算法的融合,帮助开发者迅速地完成产品落地。

根据周正宇博士公布的第一代MMSCIM和HiFi5 DSP能效比实测结果的对比显示:
当炬芯科技GEN1 MMSCIM与HiFi5 DSP均以500MHz运行同样717K参数的Convolutional Neural Network(CNN)网路模型进行环境降噪时,MMSCIM相较于HiFi5 DSP可降低近98%功耗,能效比提升达44倍。而在测试使用935K 参数的CNN网路模型进行语音识别时,MMSCIM相较于HiFi5 DSP可降低93%功耗,能效比提升14倍。
另外,在测试使用更复杂的网路模型进行环境降噪时,运行Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低89%功耗;运行Convolutional Recurrent Neural Network模型时,相较于HiFi5 DSP可降低88%功耗;运算Convolutional Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低76%功耗。
最后,相同条件下在运算某CNN-Con2D算子模型时,GEN1 MMSCIM的实测AI算力可比HiFi5 DSP的实测算力高16.1倍。
综上所述,炬芯科技此次推出的最新一代基于MMSCIM端侧AI音频芯片,对于产业的影响深远,有望成为引领端侧AI技术的新潮流。
炬芯科技Actions Intelligence助力AI生态快速发展
从ChatGPT到Sora,文生文、文生图、文生视频、图生文、视频生文,各种不同的云端大模型不断刷新人们对AI的预期。然而,AI发展之路依然漫长,从云到端将会是一个新的发展趋势,AI的世界即将开启下半场。
以低延迟、个性服务和数据隐私保护等优势,端侧AI在IoT设备中扮演着越来越重要的角色,在制造、汽车、消费品等多个行业中展现更多可能性。基于SRAM的模数混合CIM技术路径,炬芯科技新产品的发布踏出了打造低功耗端侧 AI 算力的第一步,成功实现了在产品中整合 AI 加速引擎,推出CPU+ DSP + NPU 三核 AI 异构的端侧AI音频芯片。
最后,周正宇博士衷心希望可以通过“Actions Intelligence”战略让AI真正的随处可及。未来,炬芯科技将继续加大端侧设备的边缘算力研发投入,通过技术创新和产品迭代,实现算力和能效比进一步跃迁,提供高能效比、高集成度、高性能和高安全性的端侧 AIoT 芯片产品,推动 AI 技术在端侧设备上的融合应用,助力端侧AI生态健康、快速发展。








