
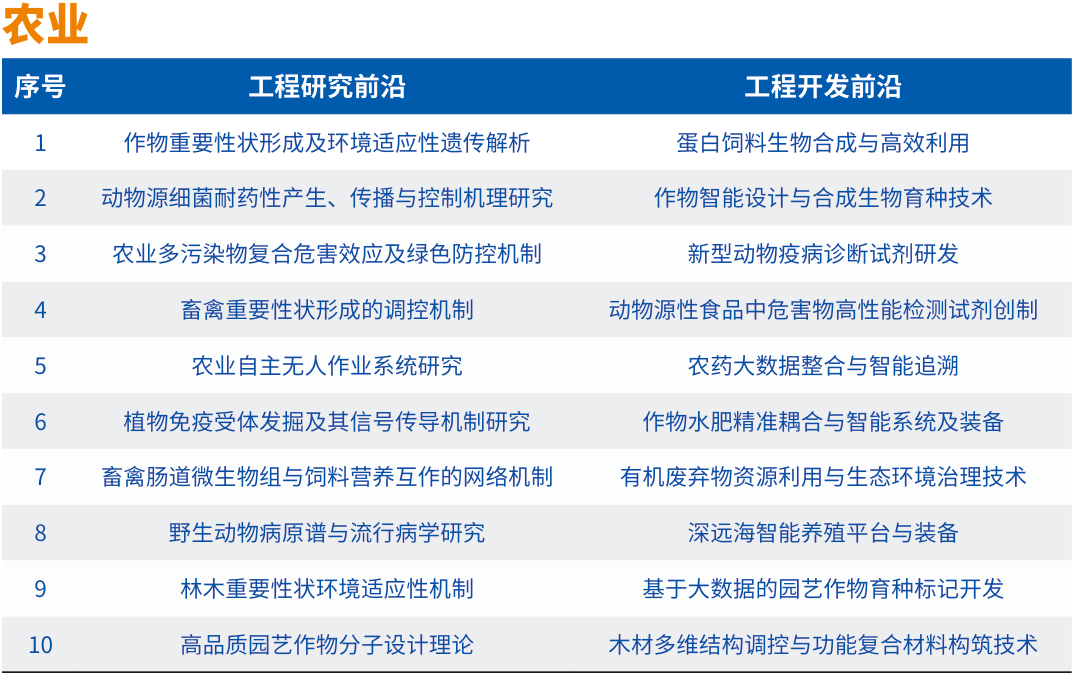
1、外国企业对用于液晶显示器的玻璃基板提起337调查申请
2、中国工程院发布2024全球工程前沿,高性能存算一体芯片等上榜
3、香港大学马毅教授谈智能本质:现在的大模型只有知识没有智能
4、浙江大学集成电路学院张亦舒研究员团队研究成果:与CMOS后道工艺兼容的高性能自整流忆阻器
5、华中科技大学于国际电子器件会议(IEDM 2024)发表浮点精度存算一体系统最新研究成果
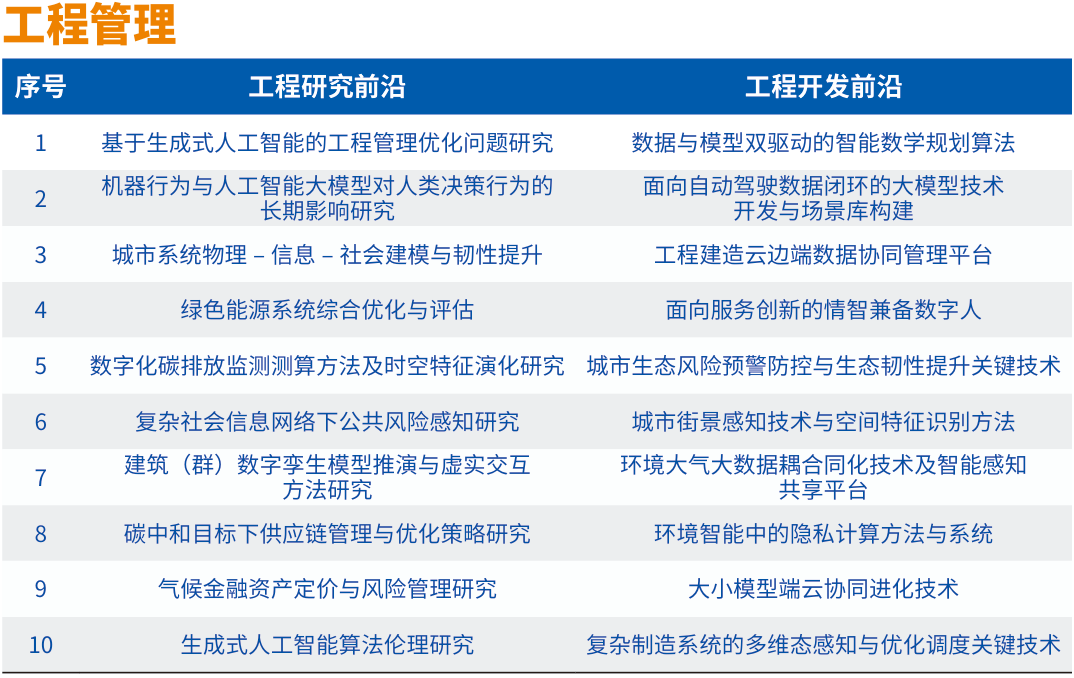
1、外国企业对用于液晶显示器的玻璃基板提起337调查申请

据中国贸易救济信息网,12月18日,美国Corning Incorporated根据《美国1930年关税法》第337节规定向美国际贸易委员会提出申请,主张对美出口、在美进口及销售的特定用于液晶显示器的玻璃基板及其下游产品和制造此类基板的方法(Certain Glass Substrates for Liquid Crystal Displays, Products Containing the Same, and Methods for Manufacturing the Same)违反了美国337条款。
中国陕西Caihong Display Devices Co., Ltd., d/b/a Irico Display Devices Co., Ltd. of China彩虹显示器件股份有限公司、美国Hisense USA Corporation of Suwanee, GA、中国广东HKC Corporation Ltd. of China惠科股份有限公司、中国香港HKC Overseas Ltd. of China、美国LG Electronics U.S.A., Inc. of Englewood Cliffs, NJ、中国广东TCL China Star Optoelectronics Technology Co., Ltd. of China TCL华星光电技术有限公司、美国TTE Technology, Inc., d/b/a TCL North America of Irvine, CA、美国VIZIO, Inc. of Irvine, CA、中国陕西Xianyang CaiHong Optoelectronics Technology Co., Ltd. of China咸阳彩虹光电科技有限公司为列名被告。
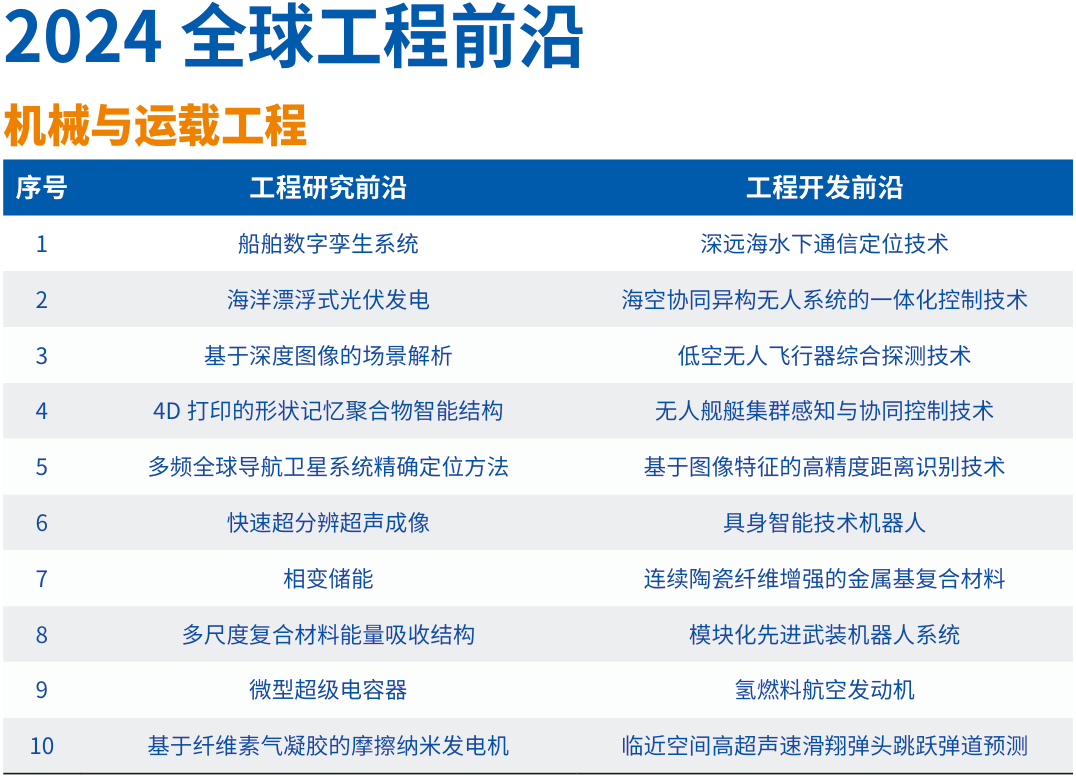
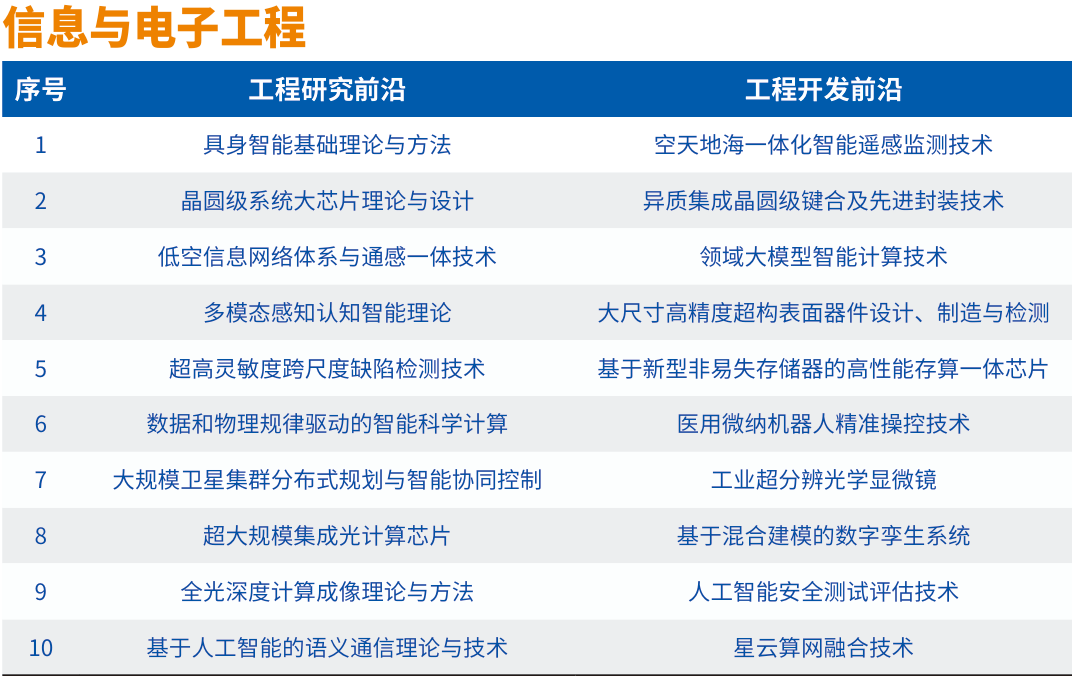
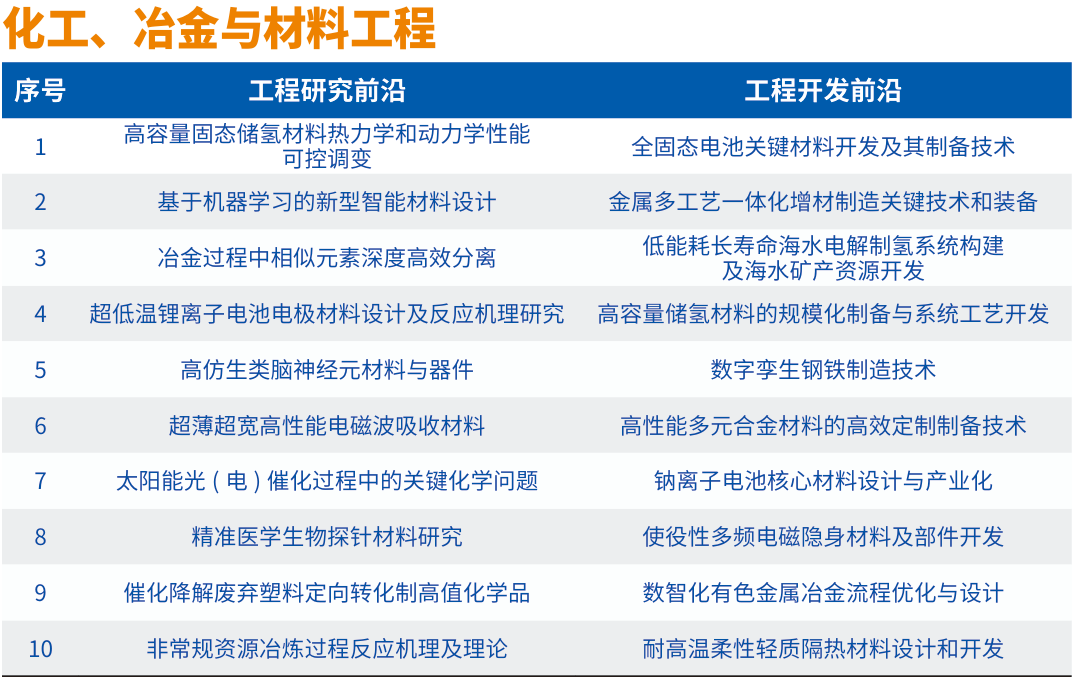
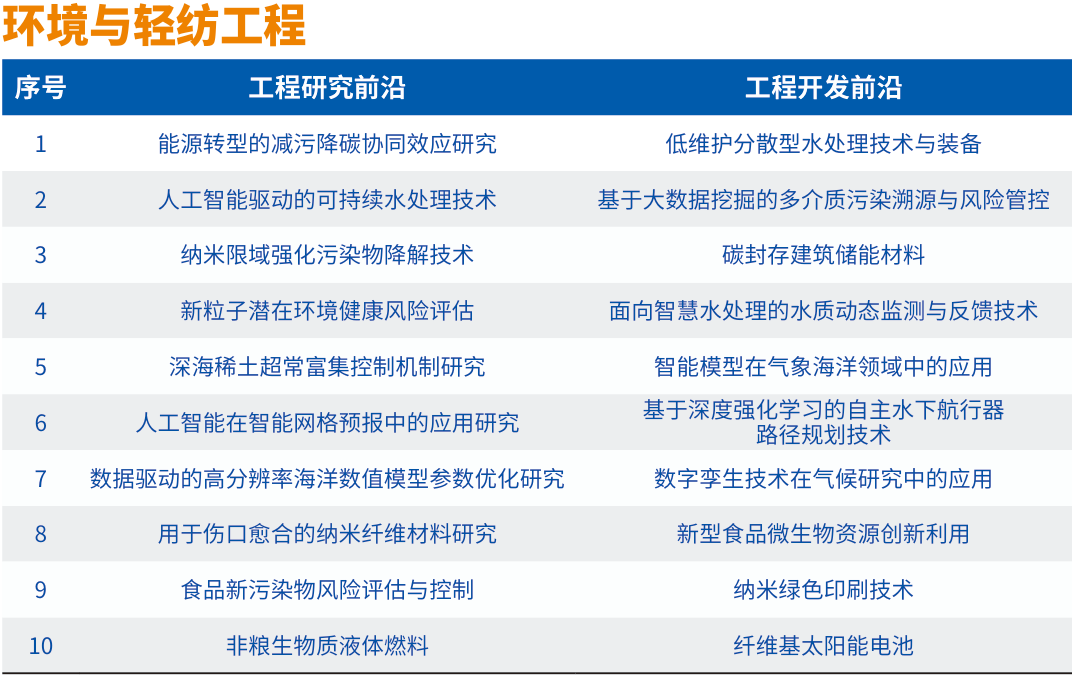
2、中国工程院发布2024全球工程前沿,高性能存算一体芯片等上榜
12月18日,中国工程院《全球工程前沿2024》报告发布。
2024全球工程前沿呈现四大特点。一是工程前沿研究向极微观深入:芯片、生物医学、量子物理等科技前沿不断深入发展,引发全球科技和产业创新颠覆性变革。二是工程前沿探索向极端条件迈进:制造、能源、材料等领域技术加速进步,抗灾、耐极温、耐腐蚀等材料性能为制造业发展和极端环境作业提供了更加可靠的保证。三是工程前沿开发向极精准拓展:全球卫星导航精确定位技术、机器人精准操控技术的发展,开辟了人类生产和生活新空间。四是工程前沿创新向极综合交叉发力:多学科交叉渗透,理论应用互相促进,传统研究和新兴研究互相结合并扩散拓展,为全球科技创新与产业创新深度融合开辟新途径。
2024年度“全球工程前沿”研究按照中国工程院9个学部所属的学科领域,通过数据分析与专家研判相结合,筛选获得92个工程研究前沿和92个工程开发前沿,并对其中最重要的27个研究前沿和27个开发前沿进行深入解读,制定重点前沿发展路线图。同时,为引领工程科技创新,项目组与《Engineering》期刊联合评选发布2024年度“全球十大工程成就”。
其中,"信息与电子工程"类异质集成晶圆级键合及先进封装技术、基于新型非易失存储器的高性能存算一体芯片等上榜。

3、香港大学马毅教授谈智能本质:现在的大模型只有知识没有智能
“过去十年人工智能在技术端上迅速发展,但在‘智能’上并没有界定清楚,把智能跟知识完全混淆在一起,一个系统有知识就有智能了吗?”
12月13日上午,在上海人工智能实验室发起并主办的首届“浦江AI学术年会”上,香港大学计算与数据科学院院长、AI讲座教授马毅进行了一场“探讨智能本质”的演讲。
马毅在演讲过程中,对现在主流定义的“人工智能”打上了问号。他认为,过去十年人工智能在技术端上迅速发展,但在“智能”上并没有界定清楚,把智能跟知识完全混淆在一起。
真正的智能是什么?马毅提到,在1956年的达特茅斯会议(Dartmouth Conference)上提出对人工智能(Artificial Intelligence)的定义,智能应该能自我纠正、改进记忆,并能自主获取新知识。目的就是一定要做人区别于动物特有的智能,比如具备抽象能力、符号运算、逻辑推理、因果分析等能力。但现在的GPT有知识但并没有“智能”。
回看过去十年,马毅认为,“人工智能”在做的工作主要集中在图像识别、图像生成、文本生成、压缩去噪、强化学习。不过,这并不是主流的大模型,现阶段相当于在做非常基础层面的工作,包括预测下一个Token(计算机术语,一种用于身份验证和授权的令牌)、下一帧图像。马毅称,Sora的核心原理其实非常简单,本科生都可以了解。
马毅说,当前,人们都在讨论单个模型,认为只要模型足够大,就能通过购买芯片和砸训练数据来实现“智能”。但他认为,这并不能解决所有问题,因为这连自主学习的能力和机制都没有实现,只是展现出人类记忆中的碎片,无论是识别还是生成,都只具备记忆的局部功能。
马毅表示,过去十年我们在智能这一阶段只做到相当于人类听觉(auditory)这一层,现在必须成系统,把多个闭环组织起来,形成对复杂的外部世界的信息整理和提取系统,这才真正相当于人类类脑的机制。

马毅提出的人工智能发展的三个阶段
他认为,现在的人工智能可以结合自然智能的发展重新定义。第一阶段,类似于DNA阶段,第二阶段,让个体能够有大脑产生记忆,能够自主地学习新的知识,包括纠正现有的知识。“现在个体和动物已经有这个能力,但真正的大模型还没有到这一阶段。”第三个阶段,是掌握人的逻辑,比如符号、抽象、数学和因果推理。
马毅会让学生做一件事,测试大模型明不明白数的概念,“很负责任地说,当前没有任何大模型有自然数的概念。”马毅说。
马毅认为,科学的发展确实到了让人兴奋、激动的时刻,大家都对智能产生了兴趣。但“实际上过去十年可能并没有进步,反而有些退步。”在马毅看来,当下的年轻科学家如果想要超越,拿下一个诺贝尔奖,一定不要随大流,要敢于坐冷板凳。1956年达特茅斯会议上一群人选择做和主流不一样的事,后期这些人都获得了图灵奖、诺贝尔奖。
马毅是AI机器视觉知名学者,1995年本科毕业于清华大学自动化专业,1997年获加州大学伯克利分校(UCB)电子工程与计算机科学硕士学位,2000年获UCB数学硕士学位和电子工程与计算机科学博士学位。博士毕业后,马毅获美国伊利诺伊大学香槟分校(UIUC)教职。
2009年,马毅正式加入微软亚洲研究院,担任视觉计算组的研究经理和首席研究员,并接手由沈向洋创办的视觉计算组(VCG),后来国际上知名的计算机视觉专家何恺明、孙剑等都是马毅当时的同事。
2014年,马毅以全职教授身份加入上海科技大学信息科学与技术学院,成为该学院在计算机视觉研究方向的带头人。2017年,他从上海科技大学离职,全职加入加州大学伯克利分校电子工程与计算机系。2023年1月1日,马毅加入香港大学,出任数据科学研究院院长。
4、浙江大学集成电路学院张亦舒研究员团队研究成果:与CMOS后道工艺兼容的高性能自整流忆阻器
近日,浙江大学集成电路学院张亦舒研究员团队在Applied Physics Letters期刊在线发表题为“Self-rectifying memristors with high rectification ratio and dynamic linearity for in-memory computing”的研究论文。本文第一作者为浙江大学集成电路学院硕士生张国滨。该工作得到了国家自然科学基金委员会和浙江省自然科学基金重大项目的资助。该论文被选为主编推荐文章(Featured Article)(见图1),并受到美国物理学联合会《科学之光》(AIP Scilight)的专访报道(见图2)。
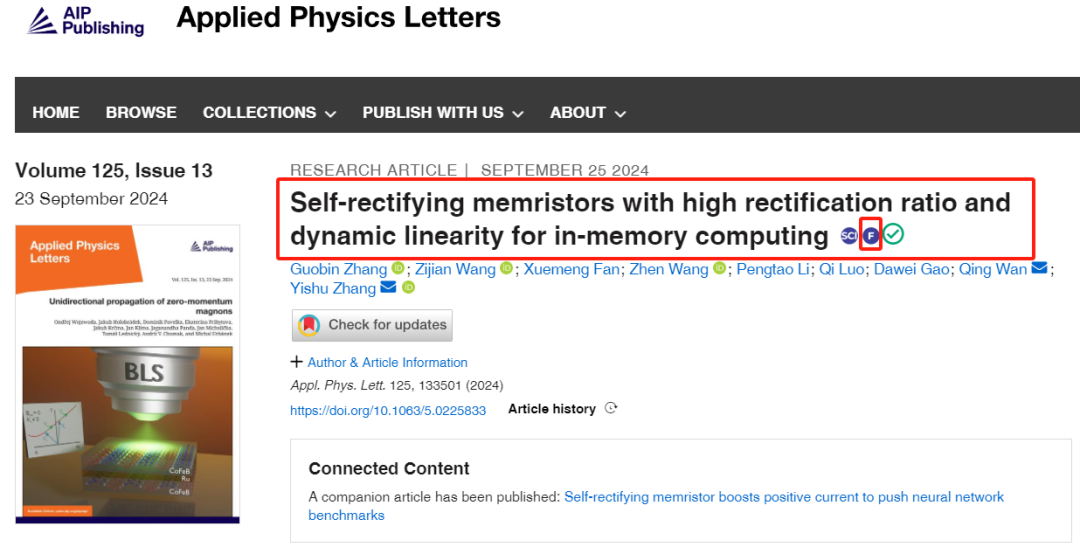
图1
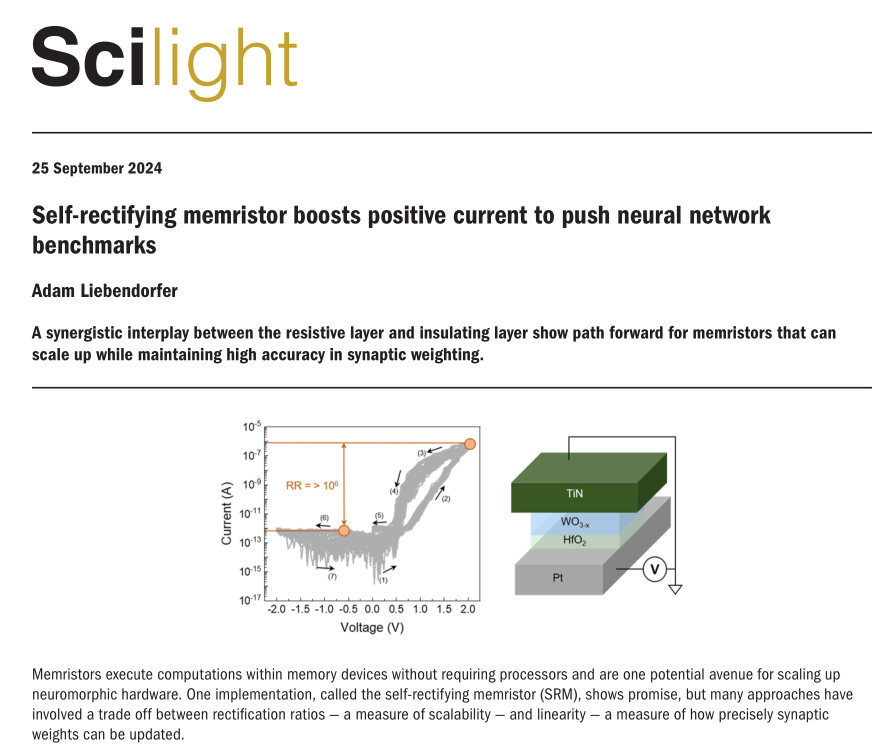
图2
课题亮点
本研究团队选用了钨的氧化物WO₃以及high-K氧化物HfO2作为核心材料。钨是CMOS工艺中常用的金属互连材料,这使得整个器件具有与现有工艺高度兼容的优势。器件采用简单的单氧化层结构,简化了制备工艺,并有效降低了工业成本。
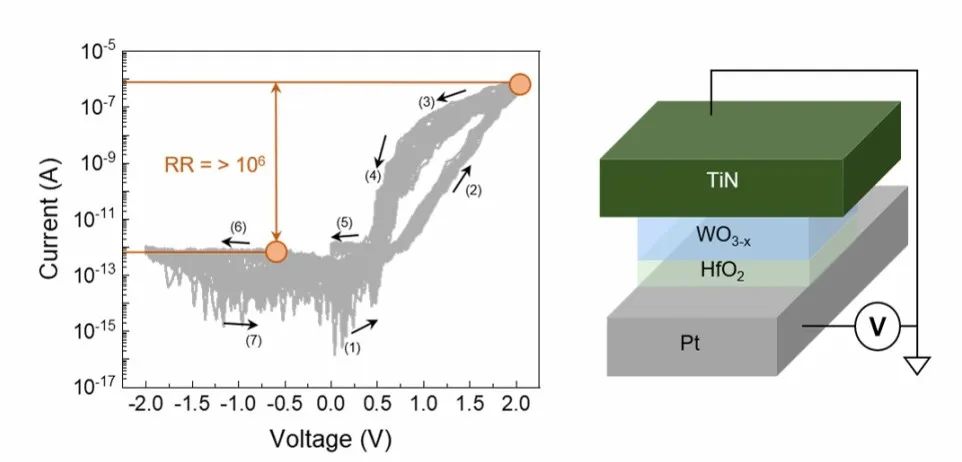
图3
这篇文章介绍了一种具有高整流比和动态线性度的自整流忆阻器(SRM),用于存内计算。在大数据时代,内存计算的需求日益迫切,而自整流忆阻器作为下一代计算架构中的关键组件,尤其能够缓解交叉阵列架构中的潜行路径电流问题。研究者们报告了一种Pt/HfO2/WO3-x/TiN结构的SRM,其整流比达到了令人印象深刻的106以上。通过系统研究WO3-x电阻层厚度对器件电导行为的影响,发现WO3-x电阻层中丰富的陷阱和HfO2的优异绝缘性能共同抑制了负电流,同时促进了正电流。模拟结果表明,基于所提出的SRM的交叉阵列可以实现超过21 Gbit的阵列规模。此外,使用这些SRM制造的人工突触展示了高达0.9973的线性度。总之,这些SRM在超大规模集成神经形态硬件方面展现出巨大潜力,为未来极低电路开销的超高效能硬件提供了指导。
这项研究不仅在材料和工艺上实现了创新,更为自整流忆阻器在标准CMOS制造工艺中的集成提供了可行方案。该成果为突破存储器件密度限制和推动神经形态计算的发展开辟了新的途径,为大规模存储和类脑计算应用提供了重要的技术支撑,展示了在后摩尔时代推进集成电路技术发展的巨大潜力。
研究背景
随着后摩尔时代的到来,集成电路的发展面临着传统架构的瓶颈,如何突破存储器件的密度限制成为关键。忆阻器作为新一代的非易失性存储器件,因其高密度集成和类脑计算潜力而备受关注。然而,传统的忆阻器在高密度阵列集成中会产生严重的串扰效应,影响器件的读取准确性,与CMOS工艺不兼容的材料体系也制约了其实际应用。
自整流忆阻器的出现为这一问题提供了有效的解决方案。自整流忆阻器在正向电压下导通,负向电压下截止,能够有效抑制反向电流,从而当集成于被动阵列时避免了读取高阻态器件时周边低阻态器件导致的渗透电流。这种特性使得无需额外的选择器件,就能实现高密度的无源交叉阵列,降低了制造成本和复杂度。
研究团队简介

张亦舒
浙江大学杭州国际科创中心百人计划研究员、求是科创学者,浙江省海外高层次人才
长期从事围绕新型存储器(RRAM, FeRAM等)实现的存算一体和神经形态计算研究,在相关领域发表学术论文50余篇,其中第一作者/通讯作者论文25篇,包括《Nature Communications》、《Advanced Materials》(4篇)、《Advanced Functional Materials》、《InfoMat》和《Nano Letters》(5篇)等;以第一发明人申请发明专利16项,授权6项,其中2项美国专利。参与编著由吴汉明院士主编的《集成电路制造大生产工艺技术》教材第17章。主持参与包括国家自然科学基金,科技部重点研发计划,浙江省重大基金在内的多项省部级项目。受邀担任International Journal of Extreme Manufacturing、Brain-X、Progress in Natural Science-Materials International和CMC-Computers Materials & Continua等国际学术期刊青年编委。获得包括第二届全国博士后创新创业银奖和国家优秀自费留学生奖学金等奖项。

张国滨 浙江大学集成电路学院2023级硕士生
研究方向为面向加密应用的自整流忆阻器。硕士期间在Advanced Materials、Nano Letters、International Journal of Extreme Manufacturing、Applied Physics Letters等期刊上发表论文六篇,公开、授权中国发明专利三项。
5、华中科技大学于国际电子器件会议(IEDM 2024)发表浮点精度存算一体系统最新研究成果
国际电子器件会议IEDM (International Electronic Device Meeting),是全球最具影响力的半导体器件领域学术会议,议题涉及半导体材料与器件、器件制造工艺、集成电路技术与应用等领域。该会议每年都会吸引世界各地的专家学者和产业界代表参加,成为了半导体领域交流与合作的重要平台。
华中科技大学集成电路学院缪向水、李祎团队,在近日于美国旧金山召开的第70届IEDM会议上报告了存算一体技术最新研究成果“Demonstration of a Floating-point Deep Neural Matrix Equation Solver using 3D Vertical ReRAM with High Energy- and Area-Efficiency”。该工作实现了国际上首个基于三维集成阻变存储器阵列的浮点精度存算一体系统,为实现高能效、高精度的AI-for-Science计算应用提供了重要方案。2019级博士生李健聪(已毕业入站从事博士后研究)和2020级博士生任升广为论文共同第一作者,李祎教授、何毓辉教授和缪向水教授为论文共同通讯作者。华中科技大学是论文唯一完成单位。
求解矩阵方程Ax=b是科学计算和具身智能等领域的基础数学问题,核心在于对方程系数矩阵A进行求逆运算。近年来,AI-for-Science相关研究表明神经网络方法能够突破传统矩阵分解方法在时间复杂度上的瓶颈,实现高效的矩阵求逆计算。但是,传统冯·诺依曼架构的计算机系统在神经网络的训练和推理过程中,面临算力不足和硬件资源消耗过大的挑战(图1)。基于阻变存储器的存算一体技术被视为高效加速神经网络计算的潜力方案。然而,求解矩阵方程通常需要浮点计算以满足精度需求,而忆阻器阵列的擦写开销及低精度模拟计算机制成为制约存算一体技术实现浮点神经网络训推性能的关键瓶颈。此外,如何突破当前平面集成阵列的算力与能效极限是另一重要难题。
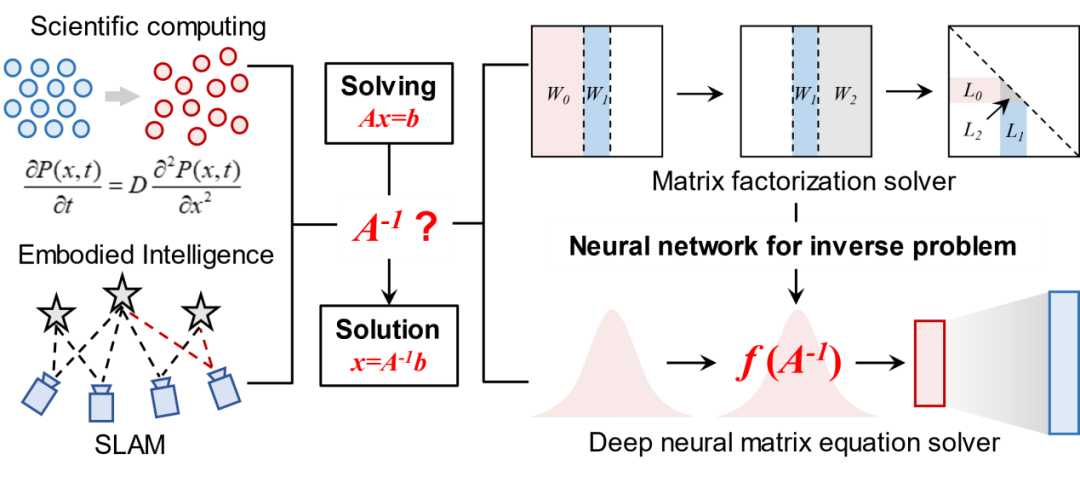
图1研究思路:基于神经网络逆运算的矩阵方程求解器
针对上述问题,团队构建了一套基于三维垂直堆叠的阻变存储器阵列(3D-V ReRAM)的存算一体神经网络训推软硬件系统,可以高效执行系数矩阵A的浮点精度逆运算及方程的浮点精度求解,并取得了以下进展:
在三维集成层面,设计并制备了4 Kb规模、4层堆叠的高一致性高可靠性3D-V ReRAM阵列。阵列在操作功耗(16.4 fJ)、擦写延时 (100 ns) 、单片可扩展性(>493 Mb)和多值编程特性(2-bit)等多方面指标均达到了国际先进水平,为实现高能效存算一体系统提供了硬件基础(图2)。

图2. 4 Kb 三维集成阻变存储器阵列
在计算架构及电路层面,针对网络高精度低开销训推这一关键挑战,提出了阻变器件本征随机性驱动的混合精度训练架构,实现了神经网络求解器的高效求逆。同时,为支持方程的高精度求解,将3D-V ReRAM阵列与任意精度存算一体技术(Arbitrary-Precision Computing-in-Memory, ArPCIM)结合,构建了支持原位单精度浮点计算的存算一体单元,突破了低精度器件实现浮点精度计算的难题(图3)。
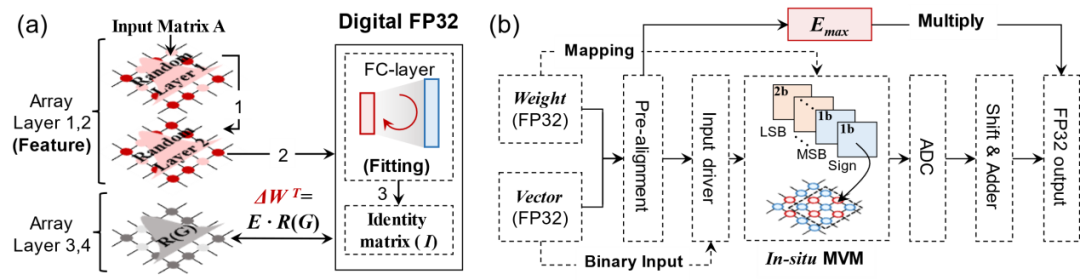
图3. 神经网络求解器的混合精度训练框架及原位浮点计算架构
所构建的存算一体原型系统实验演示了阵列中的原位FP32精度矩阵乘法计算,一维对流扩散方程的高精度求解计算误差低于10-13,相当于双精度浮点求解系统。性能评估结果表明,在22 nm节点工艺下,上述系统预期可实现11.5 TFLOPS/W的 FP32精度计算能效和大于0.63 TFLOPS/mm2的单位面积算力,相对当前最先进的NIVIDA H100 GPU可实现132倍的能效提升和7.6倍的面积效率提升(图4)。
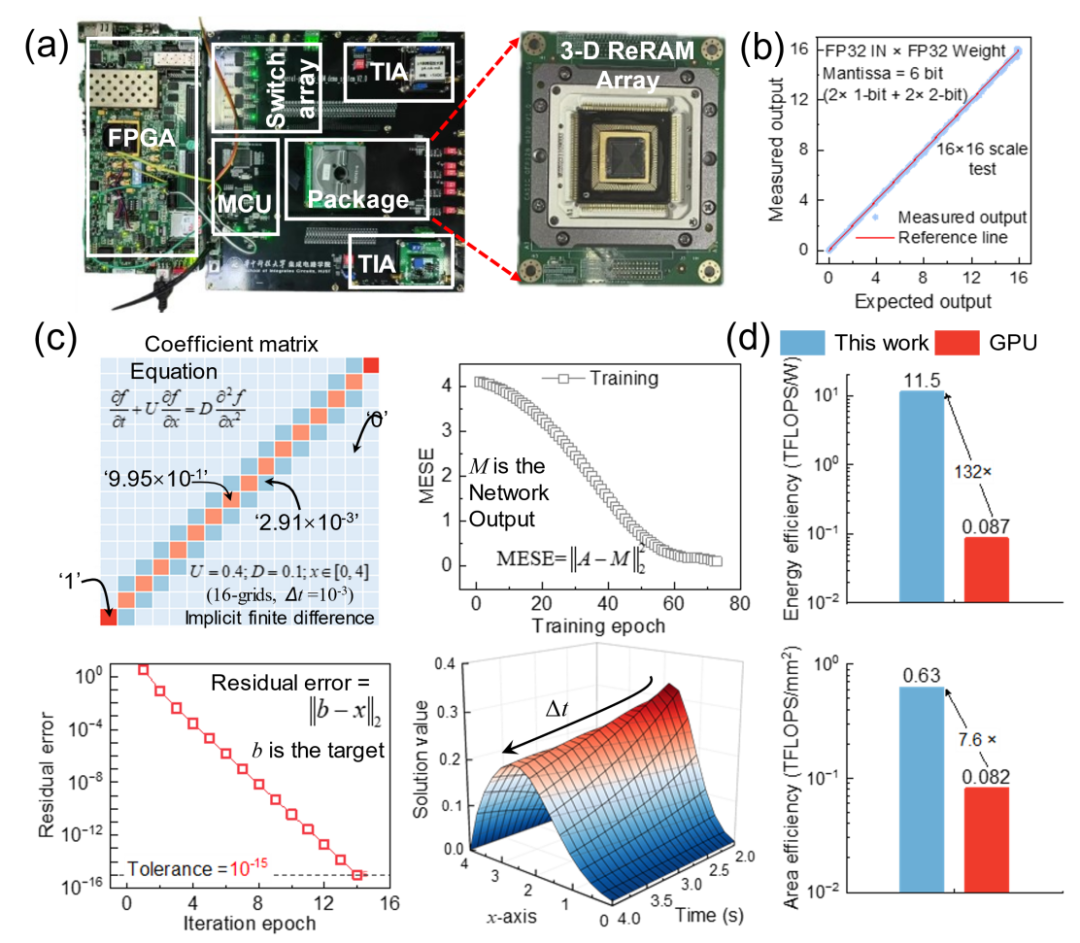
图4 存算一体系统及浮点计算任务评估
本论文是继忆阻稀疏矩阵方程求解器(Sci. Adv. 2023)、快速欠定矩阵方程求解器(IEDM 2023)、任意精度存算一体加速器(IEEE TCASI 2024)之后,团队在存算一体技术方向取得的又一重要突破。上述研究工作得到了国家科技创新2030重大研究计划、国家重点研发计划、华中科技大学基础研究支持计划等项目的资助,以及国家集成电路产教融合创新平台、先进存储器湖北省重点实验室等平台的支持。









