
DeepSeek开源模型(如V3、R1系列)在多语言理解与复杂推理任务中展现了卓越性能。这些开源模型的发布,极大地推动了AI技术的普及与发展,为研究者和开发者提供了宝贵的资源和灵感。DeepSeek的贡献不仅在于技术的领先,更在于其对开源社区的持续支持与赋能。
实战验证!从摩尔线程开始部署
作为国产全功能GPU创新企业,摩尔线程快速实现对DeepSeek蒸馏模型推理服务的高效部署,旨在赋能更多开发者基于摩尔线程全功能GPU进行AI应用创新。用户可访问以下链接一键体验。
https://playground.mthreads.com

此外,用户也可以基于MTT S80和MTT S4000进行DeepSeek-R1蒸馏模型的推理部署。早在1月28日,就已经有B站UP主在MTT S80上手动完成实践,感兴趣的用户可访问链接:
https://www.bilibili.com/video/BV18YfQYEEs2
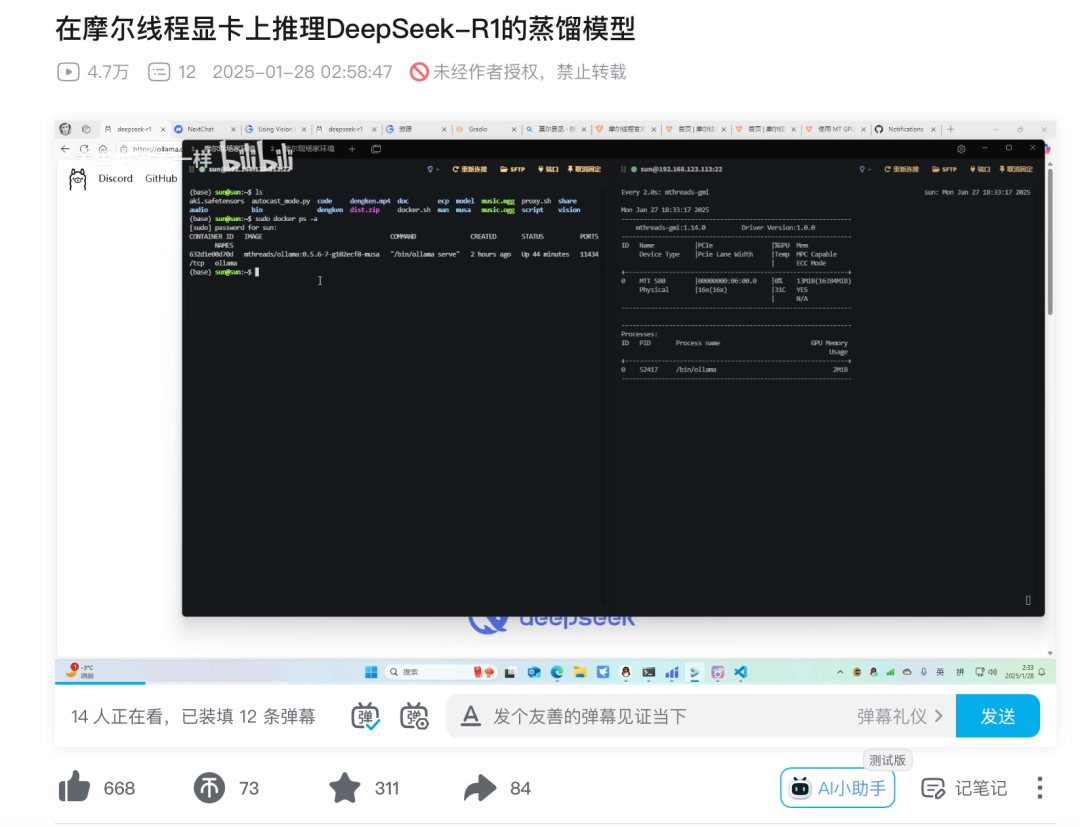
双引擎部署:开源与自研协同优化
通过DeepSeek提供的蒸馏模型,能够将大规模模型的能力迁移至更小、更高效的版本,在国产GPU上实现高性能推理。摩尔线程基于自研全功能GPU,通过开源与自研双引擎方案,快速实现了对DeepSeek蒸馏模型的推理服务部署,为用户和社区提供高质量服务。
▼ 开源框架适配:基于Ollama开源框架,摩尔线程完成DeepSeek-R1-Distill-Qwen-7B蒸馏模型的部署,并在多种中文任务中展现了优异的性能,验证摩尔线程自研全功能GPU的通用性与CUDA兼容性。
▼ 自研引擎加速:通过摩尔线程自主研发的高性能推理引擎,结合软硬件协同优化技术,通过定制化的算子加速和内存管理,显著提升了模型的计算效率和资源利用率。这一引擎不仅支持DeepSeek蒸馏模型的高效运行,还为未来更多大规模模型的部署提供了技术保障。
开放GPU集群:加速生态共建
为推进国产AI生态发展,摩尔线程即将开放自主设计的夸娥(KUAE)GPU智算集群,全面支持DeepSeek V3、R1模型及新一代蒸馏模型的分布式部署。夸娥集群集成先进推理技术与分布式计算框架,将确保大规模模型的高效稳定运行,助力开发者快速实现业务落地。
开源与国产双赢,共拓AGI未来
DeepSeek的开源模型与摩尔线程的硬件实践形成闭环,既验证了国产全功能GPU对复杂AI任务的支持能力,也为AGI技术普惠化提供了可行路径。未来,摩尔线程将持续深化与开源社区合作,通过技术开放与生态共建,推动国产全功能GPU在AI计算领域的规模化应用,为更多用户提供更智能、高效的解决方案。
▼ 关于摩尔线程
摩尔线程成立于2020年10月,以全功能GPU为核心,致力于向全球提供加速计算的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的AI计算支持。
我们的目标是成为具备国际竞争力的GPU领军企业,为融合人工智能和数字孪生的数智世界打造先进的加速计算平台。我们的愿景是为美好世界加速。








