
1、谷歌面临欧盟反垄断指控,涉嫌违反《数字市场法》
2、南大人工智能学院团队获EDA顶会DATE 2025最佳论文
3、新成果可在原子尺度上构建复杂功能结构
4、全球科研团队竞逐低成本AI模型研发新范式
5、中国人形机器人再获突破 全球首例完成前空翻特技
1、谷歌面临欧盟反垄断指控,涉嫌违反《数字市场法》

知情人士表示,Alphabet旗下谷歌将因违反旨在制衡大型科技公司权力的欧盟规则而受到指控,因为谷歌搜索结果的拟议修改未能解决欧盟反垄断监管机构及其竞争对手的担忧。
欧盟委员会此举正值欧盟与美国总统唐纳德·特朗普关系紧张之际,特朗普站在美国科技巨头一边,游说反对欧盟法规,并批评罚款是一种关税形式。这反过来引发人们对欧盟监管机构可能放松对大型科技公司的监管的担忧。
自2024年3月以来,欧盟委员会一直在调查谷歌是否违反《数字市场法》(DMA)。
一项调查的重点是谷歌是否偏袒其垂直搜索引擎,如谷歌购物、谷歌航班和谷歌酒店,以及它是否在谷歌搜索结果中歧视第三方服务。
知情人士说,即将提出的指控与此问题有关。
谷歌引用其EMEA竞争主管Oliver Bethell在去年12月的博客文章表示,公司正在努力与欧盟委员会达成平衡的解决方案。
Oliver Bethell表示,谷歌对搜索结果格式进行更多更改以安抚竞争对手可能会导致某些有用功能被删除。
谷歌近几个月宣布了一系列搜索结果格式更改,以解决来自比价网站、酒店、航空公司和小型零售商的相互冲突的需求。他们中的大多数驳回这些提议,认为这些提议不符合《数字市场法》要求。
消息人士称,欧盟反垄断监管机构也对谷歌威胁说,如果不能解决竞争对手的要求,它将在搜索结果中恢复蓝色链接感到不满。
《数字市场法》禁止谷歌在其平台上偏袒自己的产品和服务,否则将面临高达其全球年收入10%的罚款。
消息人士称,在未来几个月针对苹果和Meta Platforms的单独调查做出决定后,《数字市场法》指控可能会被发送给谷歌,这些调查的进展更加深入。
对谷歌的另一项《数字市场法》调查针对的是潜在的限制,这些限制阻碍应用程序开发人员向用户免费提供谷歌应用商店以外的优惠。
2、南大人工智能学院团队获EDA顶会DATE 2025最佳论文
据南京大学人工智能学院消息,近日,人工智能学院LAMDA组钱超教授团队在DATE 2025发表论文“Timing-Driven Global Placement by Efficient Critical Path Extraction”,获最佳论文奖。论文第一作者侍昀琦、第四作者林熙、第五作者薛轲分别是南京大学人工智能学院的硕士生、本科生和博士生,钱超教授为通讯作者,论文与华为诺亚方舟实验室合作完成。
据介绍,该工作针对大规模芯片标准单元的全局布局问题,通过高效的关键路径提取技术,覆盖所有时序(即传播时延约束,是实现芯片功能的关键)违例端点,从而精确建模时序目标,并且在优化时兼顾布线长度、布局密度、时序等多个目标;较最先进算法,在关键时序指标TNS和WNS上分别提升40.5%和8.3%。审稿人高度评价该工作,称“结果令人印象非常深刻,超过了所有先进工作”,取得显著提升。、
DATE自1994年创办以来已举办31届,今年将于3月31日至4月2日在法国里昂召开。DATE今年收到逾1200篇投稿,录用率约25%,共评选出4篇最佳论文奖(获奖率仅0.3%)。
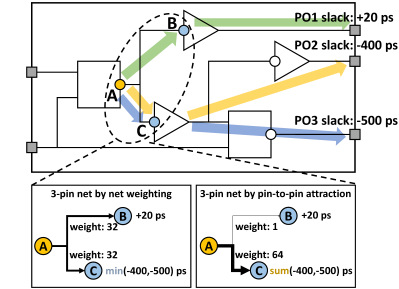
图1: 基于高效关键路径提取技术的时序目标建模
近期,AI技术在芯片设计中的应用受到了国际上高度关注。Google在Nature提出AlphaChip,应用于TPU设计,而多家EDA头部厂商也推出了AI赋能的EDA产品。芯片设计流程冗长复杂,存在大量复杂优化问题。作为人工智能的重要研究分支,演化算法受达尔文进化论启发,通过模拟“交叉变异”和“自然选择”行为,可用于求解机器学习中复杂优化问题,但这类算法几乎纯粹是“启发式”:在不少情况下有效, 但为何奏效、在何种条件下奏效却并不清楚。LAMDA组周志华教授带领俞扬教授和钱超教授长期努力,希望能够建立起相应理论基础,并对算法设计给出指导;2019年他们在Springer出版专著《Evolutionary Learning: Advances in Theories and Algorithms》,总结了他们在该方向上过去二十年的主要工作,并于2021年出版中文版《演化学习:理论与算法进展》。基于在演化学习方向的长期理论研究,近期针对芯片设计中的复杂优化问题设计出了多个原创领先算法,如针对芯片宏元件布局问题,较Google在Nature’21提出方法的布线长度缩短80%以上,较当前最先进的开源EDA工具OpenROAD的芯片最终时序指标提升超65%,在ACM SIGEVO Human-Competitive Results获奖;若干技术在华为海思落地验证,攻克华为“揭榜挂帅”难题,包括将芯片寄存器寻优效率平均提升 22.14 倍等。LAMDA组目前与华为正在进一步合作攻关,希望通过先进芯片设计缓解当前先进制造工艺局限。
3、新成果可在原子尺度上构建复杂功能结构
记者18日从国防科技大学电子对抗学院获悉,该院胡以华教授团队成功研制出一种新型核壳异质结构量子点,通过电子注入和表面等离激元效应诱导的强局域电场,实现了荧光增强94.06倍,量子产率提高32.40倍。这一成果近日发表于国际权威期刊《先进材料》。
量子点是一类微小颗粒或纳米晶体,即直径在2—10纳米(10—50个原子)之间的材料,是一种把激子在三个空间方向上束缚住的纳米结构,也被称为“人造原子”。因其独特的光电性质,量子点在光学成像、光通信、生物医学检测等领域具有广阔的应用前景。然而,传统量子点的量子产率和荧光强度有限,限制了其在实际应用中的表现。
金属量子点通常由金属材料制成,相对其他量子点,更适合用于非线性光学器件和传感器等特定应用。胡以华教授团队通过创新性地设计核壳结构,将源自银核和表面等离激元诱导的热电子迅速灌入导带,打通了M临界点的界面能垒,显著增强了量子点的光发射性能并提高了金属量子点的量子产率。该量子点可成功制备为发光光栅、光存储芯片等光电器件,还可实现溶液中重金属Cu2+离子的特异性检测。
相关学者认为,该成果意味着金属量子点领域取得了重要突破,为在原子尺度上构建复杂的功能结构提供了参考。该成果有助于未来的光电器件、光学成像和重金属检测应用,为相关领域的技术进步和产业升级提供有力支持。此外,在这种新型量子点基础上开发的特种烟幕,可实现在复杂的介质环境下的非视距散射光通信,实现快速通信链路部署。(中国日报网)
4、全球科研团队竞逐低成本AI模型研发新范式
美国斯坦福大学等机构研究团队近日宣布,在基座大模型基础上,仅耗费数十美元就开发出相对成熟的推理模型。尽管其整体性能尚无法比肩美国开放人工智能研究中心(OpenAI)开发的o1、中国深度求索公司的DeepSeek-R1等,但此类尝试意味着企业可以较低成本研发出适合自身的AI应用,AI普惠性有望增强。同时,其所应用的“测试时扩展”技术或代表一条更可持续的AI研发路径。
低成本玩转高级推理
美国斯坦福大学和华盛顿大学研究团队近日宣布研发出名为s1的模型,在衡量数学和编码能力的测试中,可媲美o1和DeepSeek-R1等。研究团队称,训练租用所需的计算资源等成本只需约几十美元。
s1的核心创新在于采用了“知识蒸馏”技术和“预算强制”方法。“知识蒸馏”好比把别人酿好的酒进一步提纯。该模型训练数据是基于谷歌Gemini Thinking Experimental模型“蒸馏”出的仅有1000个样本的小型数据集。
“预算强制”则使用了AI模型训练新方法——“测试时扩展”的实现方式。“测试时扩展”又称“深度思考”,核心是在模型测试阶段,通过调整计算资源分配,使模型更深入思考问题,提高推理能力和准确性。
“预算强制”通过强制提前结束或延长模型的思考过程,来影响模型的推理深度和最终答案。s1对阿里云的通义千问开源模型进行微调,通过“预算强制”控制训练后的模型计算量,使用16个英伟达H100 GPU仅进行26分钟训练便达成目标。
美国加利福尼亚大学伯克利分校研究团队最近也开发出一款名为TinyZero的精简AI模型,称复刻了DeepSeek-R1 Zero在倒计时和乘法任务中的表现。该模型通过强化学习,实现了部分相当于30亿模型参数的大语言模型的自我思维验证和搜索能力。团队称项目训练成本不到30美元。
“二次创造”增强AI普惠性
清华大学计算机系长聘副教授刘知远接受记者采访时说,部分海外研究团队使用DeepSeek-R1、o1等高性能推理大模型来构建、筛选高质量长思维链数据集,再用这些数据集微调模型,可低成本快速获得高阶推理能力。
相关专家认为,这是AI研发的有益尝试,以“二次创造”方式构建模型增强了AI普惠性。但有三点值得注意:
首先,所谓“几十美元的低成本”,并未纳入开发基座大模型的高昂成本。这就好比盖房子,只算了最后装修的钱,却没算买地、打地基的钱。AI智库“快思慢想研究院”院长田丰告诉记者,几十美元成本只是最后一个环节的算力成本,并未计算基座模型的预训练成本、数据采集加工成本。
其次,“二次创造”构建的模型,整体性能尚无法比肩成熟大模型。TinyZero仅在简单数学任务、编程及数学益智游戏等特定任务中有良好表现,但无法适用于更复杂、多样化的任务场景。而s1模型也只能通过精心挑选的训练数据,在特定测试集上超过早期版本o1 preview,而远未超过o1正式版或DeepSeek-R1。
最后,开发性能更优越的大模型,仍需强化学习技术。刘知远说,就推动大模型能力边界而言,“知识蒸馏”技术意义不大,未来仍需探索大规模强化学习技术,以持续激发大模型在思考、反思、探索等方面的能力。
AI模型未来如何进化
在2025年美国消费电子展上,美国英伟达公司高管为AI的进化勾画了一条路线图:以智能水平为纵轴、以计算量为横轴,衡量AI模型的“规模定律”呈现从“预训练扩展”、到“训练后扩展”,再到“测试时扩展”的演进。
“预训练扩展”堪称“大力出奇迹”——训练数据越多、模型规模越大、投入算力越多,最终得到AI模型的能力就越强。目标是构建一个通用语言模型,以GPT早期模型为代表。而“训练后扩展”涉及强化学习和人类反馈等技术,是预训练模型的“进化”,优化其在特定领域的任务表现。
随着“预训练扩展”和“训练后扩展”边际收益逐渐递减,“测试时扩展”技术兴起。田丰说,“测试时扩展”的核心在于将焦点从训练阶段转移到推理阶段,通过动态控制推理过程中的计算量(如思考步长、迭代次数)来优化结果。这一方法不仅降低了对预训练数据的依赖,还显著提升了模型潜力。
三者在资源分配和应用场景上各有千秋。预训练像是让AI模型去学校学习基础知识,而后训练则是让模型掌握特定工作技能,如医疗、法律等专业领域。“测试时扩展”则赋予了模型更强推理能力。
AI模型的迭代还存在类似摩尔定律的现象,即能力密度随时间呈指数级增强。刘知远说,2023年以来,大模型能力密度大约每100天翻一番,即每过100天,只需要一半算力和参数就能实现相同能力。未来应继续推进计算系统智能化,不断追求更高能力密度,以更低成本,实现大模型高效发展。(新华网)
5、中国人形机器人再获突破 全球首例完成前空翻特技
2月24日,昨日,深圳众擎机器人科技有限公司宣布成功完成全球首例机器人前空翻特技,这一成果标志着机器人在运动与灵活性方面取得重大进展。


据悉,与完成后空翻相比,完成前空翻对机器人的动态平衡、瞬间加速和精准落地提出了更高的要求。工程师团队经过精确计算,使机器人在空翻过程中保持稳定,并在落地时完美支撑重心,实现了这一高难度动作。
据了解,众擎科技通过对机器人运动学的深入研究,结合智能控制算法与先进的传感器技术,成功攻克了这一技术难题,实现了这一技术突破。
深圳市众擎机器人科技有限公司成立于2023年10月,专注于通用智能机器人及行业场景解决方案的研发与生产,产品涵盖人形机器人及相关领域。众擎在2024年10月推出首款全尺寸通用人形机器人SE01,首次实现了自然拟人步态。相比于动作僵硬、能耗高、适应性差的机械步态,拟人步态表现出更高的灵活性和效率,实现身体各部位的协调运动。据悉,该公司近日完成一轮 2 亿元融资,资金来源为中东。(凤凰网)









