

近日,2025玄铁RISC-V生态大会在京召开,全球数百家企业及机构齐聚,探讨RISC-V与AI融合的技术路径与生态前景。

在DeepSeek等大模型推动AI向端侧渗透的浪潮下,边缘算力需求激增,AI芯片行业正经历从“云优先”到“云边协同”的范式转变。作为“玄铁优选伙伴”,爱芯元智携自研爱芯通元混合精度NPU亮相,展示其如何以开放生态与专用架构,助力大模型在边端侧高效落地。
大模型“轻量化”浪潮加速边缘智能
DeepSeek-R1热潮所带来的大模型训练与推理成本降低,推动AI应用加速从云端下沉至边缘设备。IDC数据显示,未来几年边缘侧数据量将占总数据量的50%,这些数据需依赖端侧AI芯片进行实时处理,进一步推动边缘AI芯片市场扩张。
然而,边缘场景的碎片化与严苛的功耗限制,也对传统算力架构提出了挑战。GPU虽在并行计算上具备优势,但其高功耗与固定架构难以适配多样化的端侧需求;而通用CPU的灵活性虽高,却受限于算力密度。在此背景下,通过RISC-V处理器的高效调度与NPU的专用加速,实现算力与能效的平衡已成为共识。
为边缘智能而来 爱芯通元NPU原生支持主流大模型
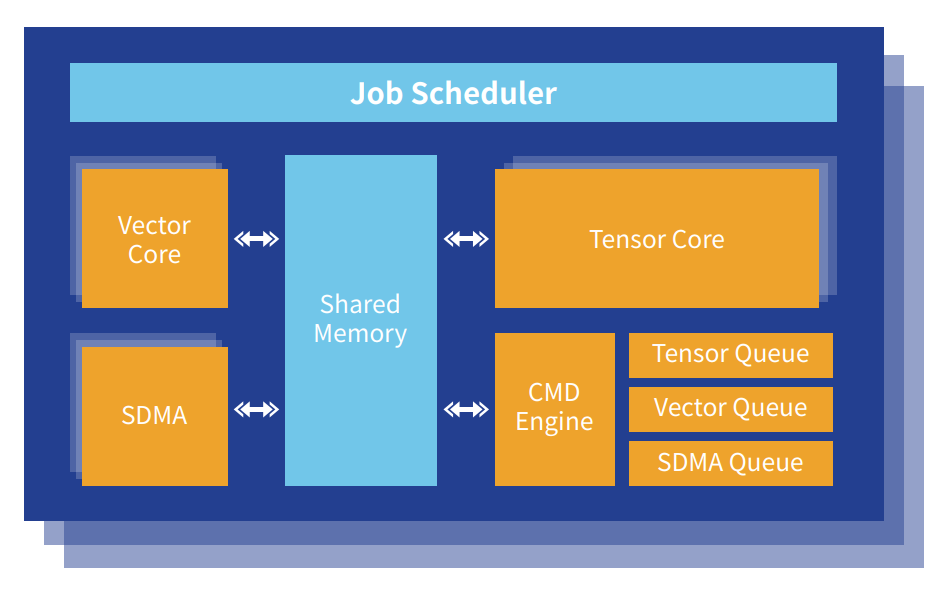
作为“玄铁优选伙伴”,爱芯元智现场展示的爱芯通元混合精度NPU,就是针对边缘场景设计的专用AI处理器。其以算子为原子指令集,原生支持DeepSeek、Llama、Qwen等主流大模型结构,通过多线程异构多核设计与混合精度优化,在保证高算力密度的同时显著降低功耗。以典型视觉任务SwinT为例,该NPU可实现199 FPS/W的超低能耗,能效远超传统方案。
此外,NPU的灵活扩展能力支持算力从4T至256T动态适配,覆盖从智能摄像头到车载计算平台的多样化需求。在智慧城市领域,其硬件压缩单元与算法优化技术可明显减少带宽占用;在智能驾驶场景中,内置的Transformer加速模块可大幅降低BEV(鸟瞰图)模型推理延迟。这些特性使其成为边缘大模型落地的关键技术支撑。
RISC-V与NPU的“双轮驱动”

RISC-V的开放性为AI芯片定制化提供了底层支持。据RISC-V国际基金会数据,2024年全球RISC-V芯片出货量已超100亿颗,其中30%应用于AI加速场景。爱芯元智深度融入玄铁生态,将自研爱芯通元NPU与玄铁RISC-V处理器结合,提供从感知、计算到数据处理的端到端解决方案。
此次大会上,基于玄铁C920处理器的AI PC原型机成功运行Llama、DeepSeek等模型,验证了“RISC-V+NPU”异构架构在端侧大模型部署中的可行性。而爱芯通元NPU单位能耗性能领先行业平均水平,为边缘设备运行复杂AI模型树立了新标杆。
当前,AI芯片行业竞争已从单纯算力比拼转向场景化适配能力。爱芯元智以“普惠AI造就美好生活”为使命,通过爱芯通元NPU与玄铁RISC-V的深度协同,成为驱动行业从“云端集中”迈向“边缘智能”的关键力量。
AI技术和应用的持续革新,带来边缘AI的算力爆发。爱芯元智联合创始人、副总裁刘建伟表示,爱芯通元NPU与玄铁RISC-V IP的结合,打造出高能效AI计算平台,满足边端不同场景下对感知、计算和数据处理能力的需求。未来,双方将继续强强联合,探索AI算力提升及行业落地,我们相信,高效AI推理芯片的应用也将迎来更广阔的天地。





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000