

下一个可能颠覆全球人工智能行业的“DeepSeek”也可能来自中国。
中国已经孕育了多个有前景的AI初创公司和项目,而其领先的互联网企业多年来一直在投资和开发支持这些新企业的基础设施。伴随着DeepSeek的经验让人们质疑是否需要像英伟达公司那样昂贵的尖端AI硬件,中国新兴AI公司的前景似乎正在改善。
中国AI公司异军突起
2025年,阿里巴巴的Qwen平台已成为能与DeepSeek以及ChatGPT的创造者OpenAI相匹敌的领先竞争者之一。近日,它发布了最新的开源QwQ模型,声称该模型只需少量数据就能达到与DeepSeek相当的性能。另一个常被提及的竞争者是字节跳动及其豆包大模型。此外,腾讯控股的有道AI聊天机器人在3月初一度登顶iPhone下载排行榜。
随着中国企业巧妙应对贸易限制并开发更高效的AI模型,中国诞生了一批值得关注的新兴公司和产品。
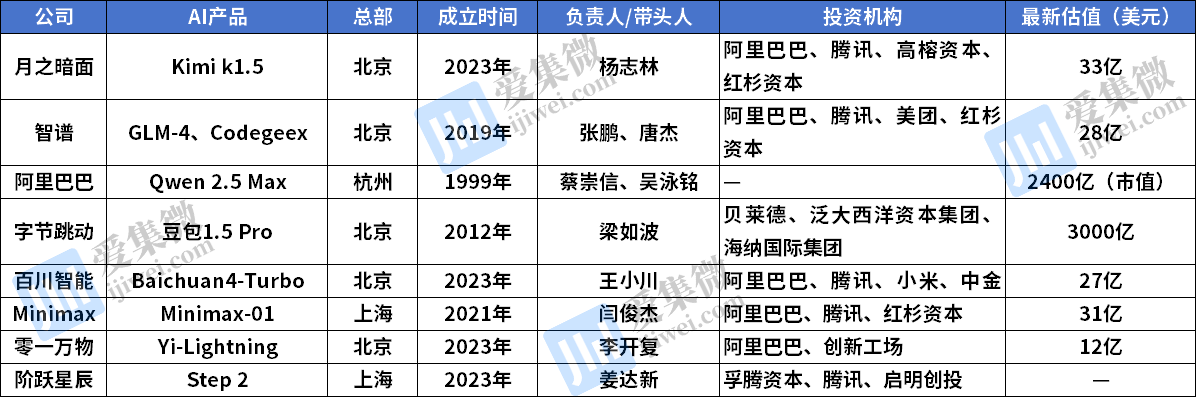
月之暗面
Moonshot(月之暗面)由清华大学助理教授杨志林创立,他早先曾在Meta Platforms Inc.和Alphabet Inc.旗下的谷歌从事AI项目。Moonshot的最新发布利用强化学习来加速和扩展训练过程。与DeepSeek的R1推理模型在同一天宣布,其工作原理相似。推理模型使用思维链方法来查找和改进查询的答案。Kimi k1.5专为更简短的回复而设计,支持多达200万个中文字符的上下文,涵盖从先前对话到用户意图和情境的一切内容。
智谱
智谱发布了一系列应用和工具,包括一个可以模拟用户在智能手机或网页浏览器上操作的自主代理。其语音AI模型包括对人类语调、情感和不完美之处(如填充词、停顿和偶尔的喘息)的模拟。该公司在拜登政府最后几天被美国商务部列入黑名单,进一步限制了其获取美国AI芯片的途径。清华大学将智谱的成功归功于其校友唐杰,其团队牵头了公司的模型开发。唐杰还曾在杨志林在清华大学学习时指导过他。
阿里巴巴
中国电商和云计算领导者在其模型最新版本发布后不久,DeepSeek在全球引起轰动,宣称取得了更好的基准结果。阿里巴巴与腾讯控股一起,在名单上大多数其他竞争者中持有股份,即便与它们存在竞争关系。在首席执行官(CEO)吴泳铭的领导下,该公司正重新聚焦其核心优势,其中云计算和崛起的AI浪潮是关键组成部分。
字节跳动
中国最受欢迎的消费者聊天机器人来自TikTok的母公司。字节跳动自认为在AI领域还有追赶空间,并将其作为首要任务。豆包采用混合专家(MoE)机器学习方法构建,这在中国的多个AI模型中很常见。豆包凭借其机智、类人的对话和用户友好的界面在中国获得了关注。其会议摘要和图像生成功能也吸引了年轻用户。
百川智能
百川智能的最新模型采用了一种称为深度思考的技术——一种复杂的推理和问题解决方法,模仿人类解决问题的过程。它适用于文本、语言和视觉。公司还提供一种基于证据的狭窄医疗模式,旨在为医疗专业人士和学者检索医疗研究和数据。创始人王小川在创办百川之前,将他的搜索引擎搜狗卖给了腾讯。
Minimax
Minimax使用其所谓的闪电注意力机制,有效将极长的数据序列分解为更小、更易管理的数据块。该模型旨在优先处理长文本中最重要的部分,而不被细节拖累。创始人闫俊杰出自中国科学院,并在清华大学进一步深造。他在离开商汤科技创立Minimax之前,曾担任该公司副总裁。
零一万物
与DeepSeek一样开源的01.AI,2024年10月发布了Yi-Lightning混合专家模型,在备受关注的基准测试中紧随OpenAI和谷歌的闭源模型之后。这家初创公司声称其AI模型的训练成本远低于行业领导者,并在商业化服务方面走得最远,正在为各种行业应用构建解决方案。它还宣布了与阿里巴巴的联合开发项目。
阶跃星辰
Stepfun的最新产品是一个万亿参数的大型语言模型,也依赖于MoE技术。MoE是一种将模型划分为子集的方法,每个子集在处理特定类型的数据或任务方面具有专长,通过仅激活每个任务所需的专家子网络来提高效率。首席执行官姜达新此前曾领导微软公司在亚洲的研究工作。上海政府支持的一家基金是该企业的首批支持者之一。
中美三大模型对比:中企模型便宜20-40倍
2024年12月,DeepSeek发布了大语言模型V3,并在今年1月推出了推理模型 R1。根据伯恩斯坦研究公司的分析,这些模型在性能上与OpenAI 的同类模型相当甚至更优秀,但价格“便宜20-40倍”。
3月17日,百度发布了文心大模型4.5和推理模型X1。百度称,文心大模型4.5是其首个原生多模态大模型,在多项测试中表现优于GPT4.5,API调用价格仅为GPT4.5的1%。X1为深度思考模型,性能对标DeepSeek-R1,调用价格约为R1的一半。
这再次引起了美国媒体对于大模型成本的关注。为此,《商业内幕》专门拿百度的新模型与DeepSeek、OpenAI进行了对比。
Tokens是AI模型处理中的最小数据单位。企业会根据模型处理时的输入Tokens数量和生成的输出Tokens数量来定价。
以文心4.5大模型为例,它的输入价格为0.004元/千tokens,输出0.016元/千tokens,约为GPT4.5价格的1%,但它仍高于DeepSeek V3。
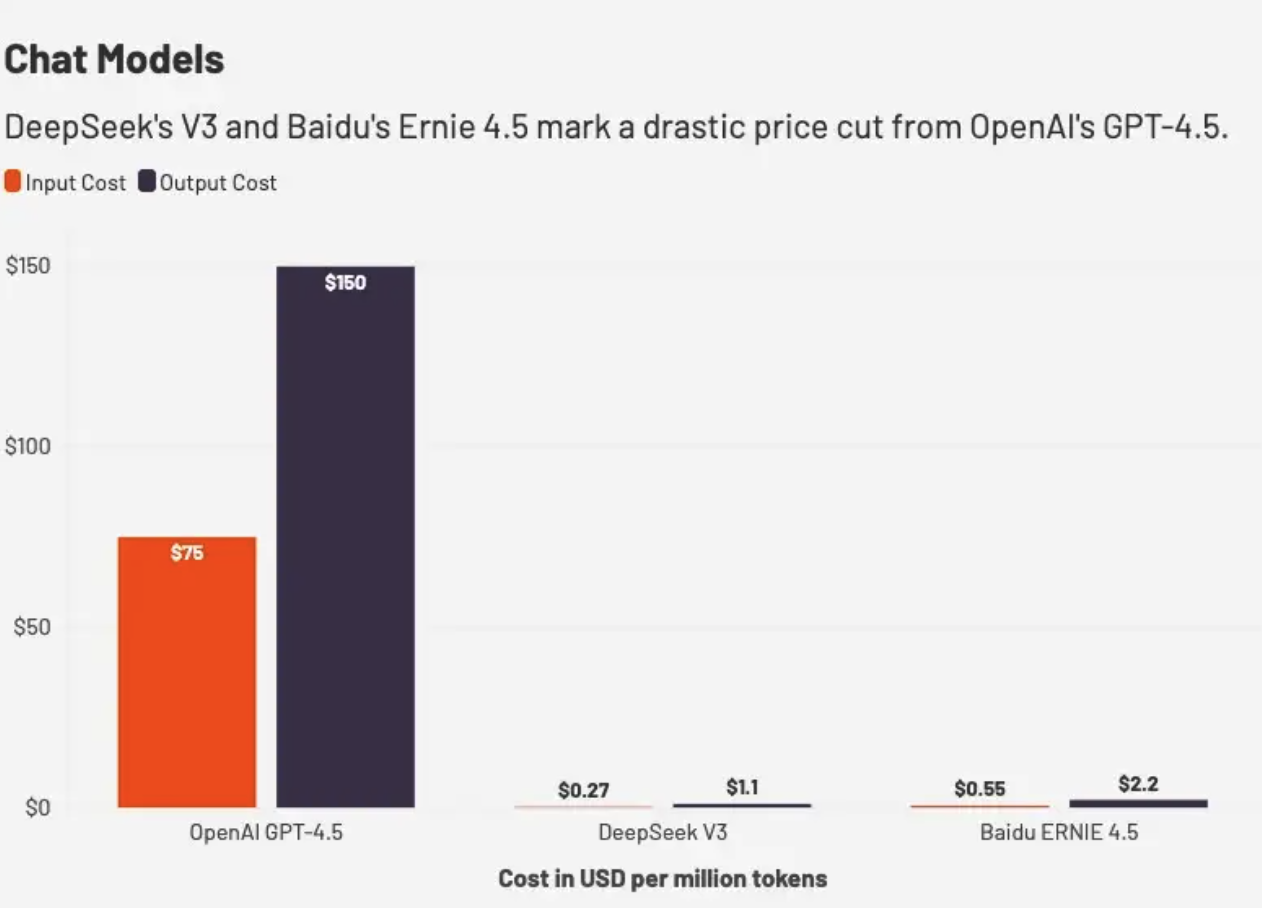
基础模型价格对比
在推理模型方面,文心X1的定价是最便宜的,不到OpenAI o1模型的2%。
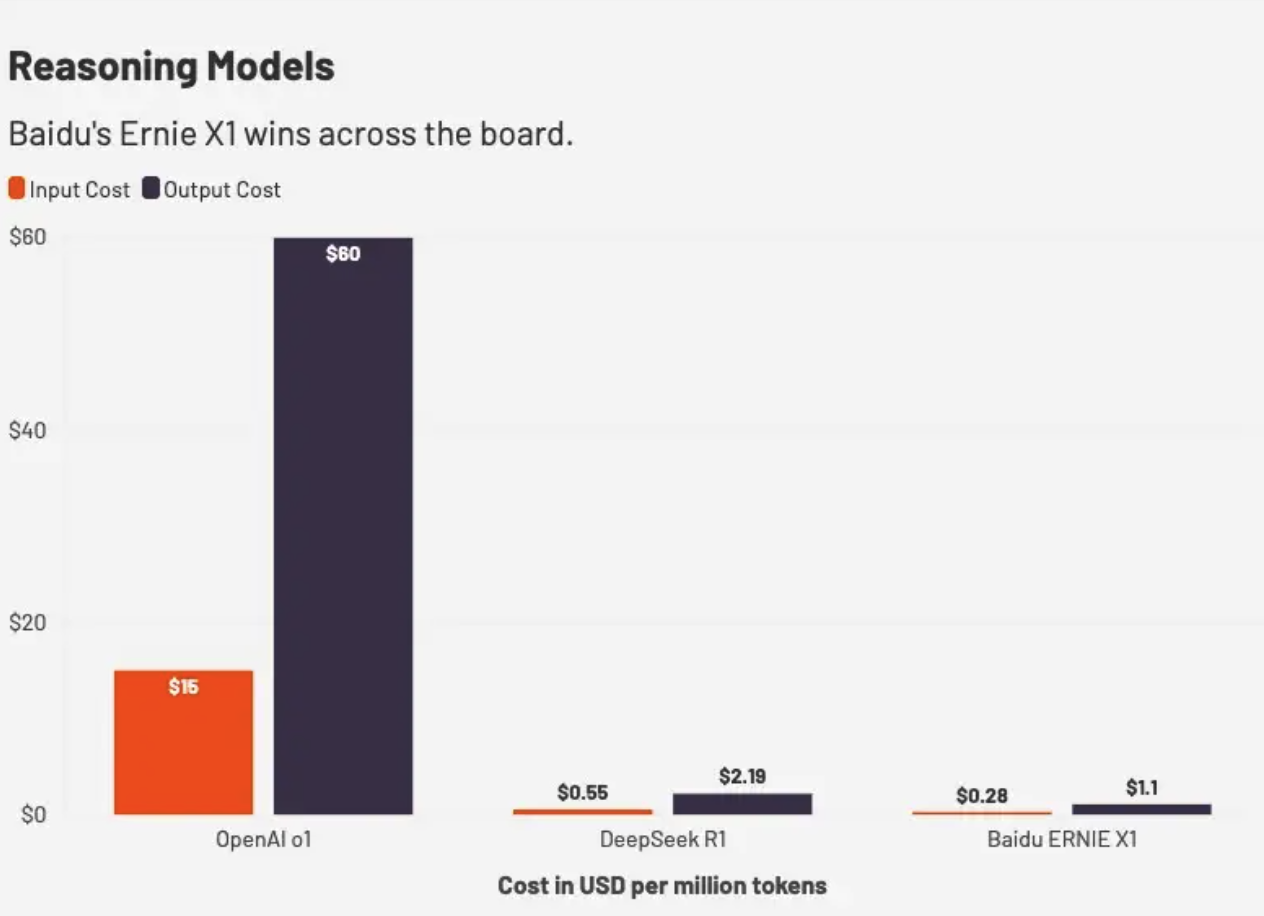
推理模型价格对比
中国AI模型已接近OpenAI o1级智能 未来可期
独立的AI评估机构Artificial Analysis表示,中国人工智能实验室已逐步赶上美国人工智能实验室:随着DeepSeek的R1模型的发布,中国实验室的模型现在正接近o1级智能。推理模型最早由OpenAI在2024年第三季度引入。几个月内,以DeepSeek为代表的中国竞争对手已基本复制了o1的智能水平。目前,多家中国AI实验室已经拥有前沿级别的推理模型。
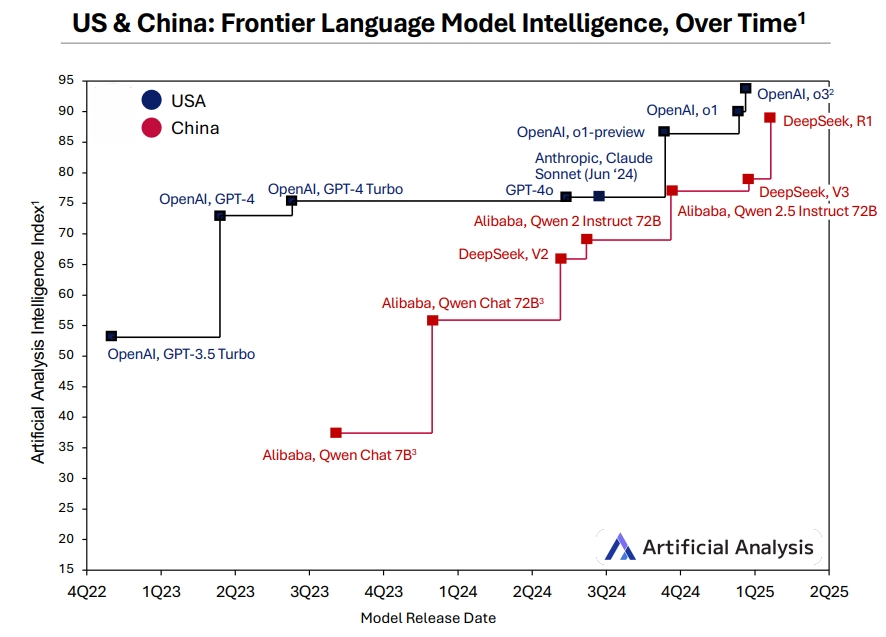
中美前沿大语言模型
该机构指出,虽然中国的AI实验室较晚加入AI竞赛,但在2024年,它们在智能方面与前沿的美国模型之间的差距显著缩小。当OpenAI推出o1时,中国实验室在几个月内开发出了一个性能相当的模型(DeepSeek的R1)。
此外在2025年初,包括阿里云、深视、明略、腾讯、智谱和通义等中国人工智能实验室纷纷发布了前沿推理模型。发布的速度和频率表明,中国人工智能实验室在2025年已不再是
落后者。
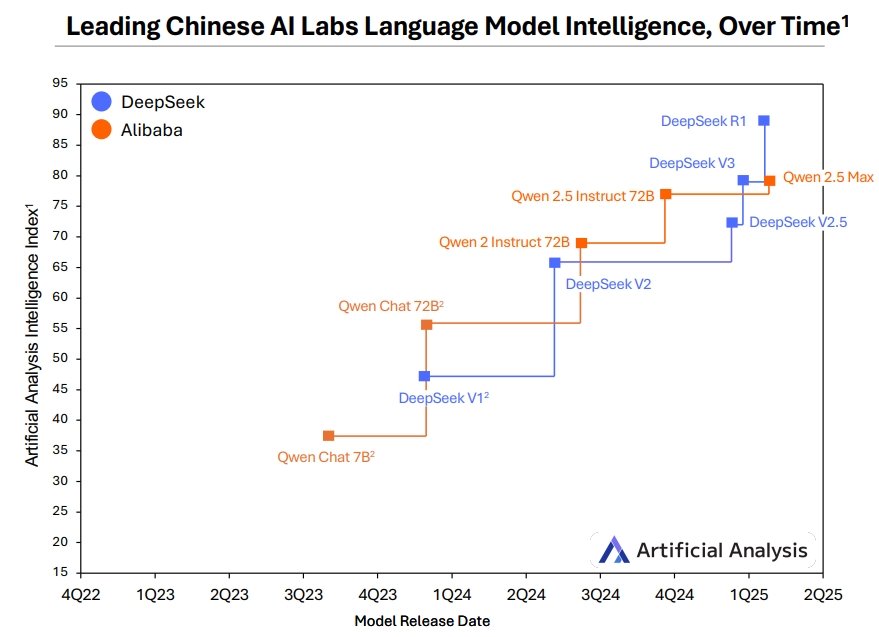
中国领先的AI实验室大语言模型
Artificial Analysis称,在美国继续在情报前沿领域保持总体领先地位的同时,中国与之的距离已不再遥远。很少有其他国家能够展示出同等水平的训练能力。
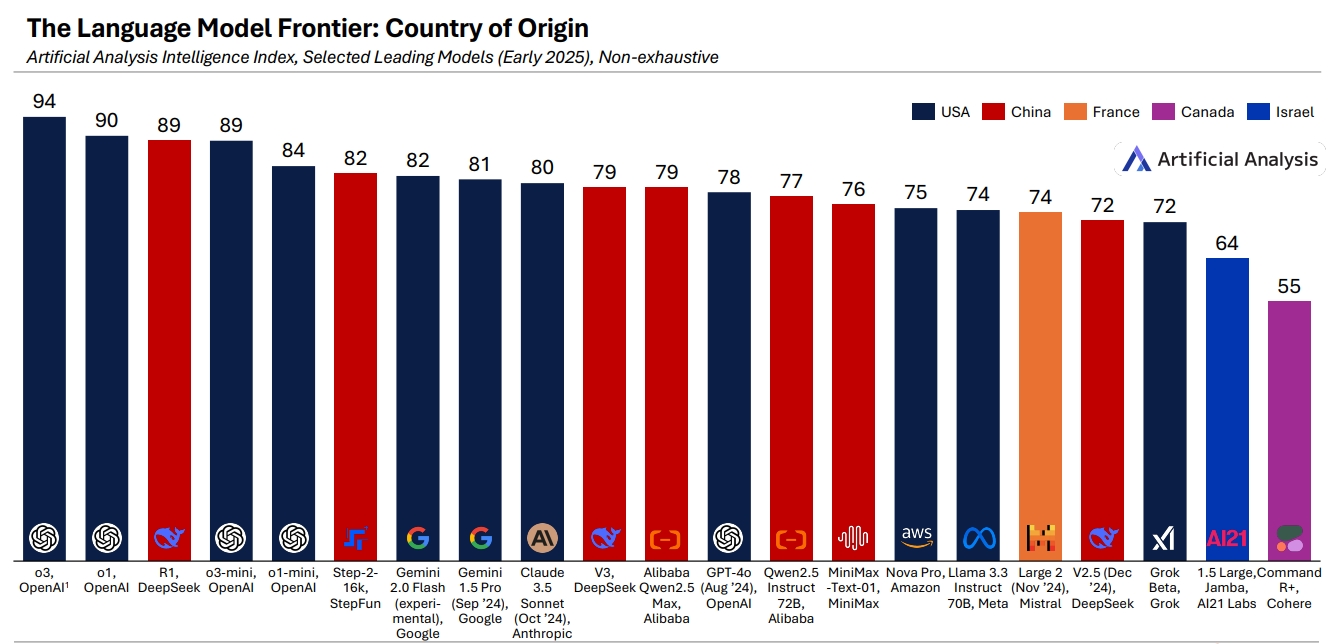
前沿大预言模型归属地划分
展望未来,中国AI公司有望继续保持强劲的发展势头。一方面,政府对科技创新的重视和支持将为AI产业提供持续的动力和良好的发展环境。另一方面,企业和科研机构将不断加大研发投入,吸引和培养更多的专业人才,进一步推动AI技术的创新和应用。在全球AI竞争日益激烈的背景下,中国AI公司将凭借其独特的优势,积极拓展国际市场。可以预见,未来中国AI产业将在全球舞台上发挥更加重要的作用,甚至有可能引领全球AI行业的发展潮流。(校对/赵月)





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000