

人工智能将彻底改变处理器芯片研究
—大模型研讨课的总结
陈云霁(处理器芯片全国重点实验室主任)
从2024年10月31日至2025年1月2日,我组织处理器芯片全国重点实验室的一批优秀青年科研人员,举办了十期大模型研讨课。由处理器芯片全国重点实验室来讲授人工智能的前沿技术大模型,听起来好像是少林和尚来教武当太极拳,有点怪。但我认为,办大模型研讨课,对于处理器芯片全国重点实验室来说,是极其必要的。
诚然,已经有越来越多的芯片研究者开始关注人工智能。但总的来说,大部分芯片研究者是把人工智能仅仅当作芯片在科学计算、事务处理、数据库之外的又一个应用负载。然而,人工智能对于处理器芯片发展的意义远远不止于此。人工智能正在催生科学研究的新范式,也必将彻底改变处理器芯片的发展。尤其是在大模型出现后,诺贝尔奖得主G. Hinton说:“有时我认为这(人工智能)就像外星人登陆了,而人们还没有意识到。[1]”所以,我希望通过这次研讨课,能让实验室的老师和同学们更多地了解人工智能最前沿的大模型,更早地感受大模型即将带来的时代变革。这对于一个代表中国参与处理器芯片国际科技竞争的全国重点实验室来说,极其重要。
非常欣慰的是,这次的大模型研讨课取得了很好的效果,吸引了上千名参与者。参与者中不仅有我们实验室各个课题组的老师同学,还有中科院软件所、中科院自动化所、清华、北大、字节跳动、腾讯等机构的同行。这一方面说明讲课的青年科研人员们很优秀。他们不仅有一线的大模型实战经验,也有科学史的宏大时空观,因此能将大模型从基础理论到前沿技术,从模型设计到实际应用,层层递进、系统性地呈现给大家,使得课程内容丰富且深入。我自己在出差的旅途中,也经常会在B站上观看课程的录像[2],每次观看都有新的收获(包括对DeepSeek进展最初的了解)。另一方面也说明来听课的老师和同学很有前瞻眼光,敏锐地意识到了人工智能和大模型给处理器芯片带来的新机遇,愿意主动学习,拥抱变化。这种前瞻眼光,是抢占智能时代处理器芯片科技制高点的宝贵凭借。
PART ONE
人工智能正在改变科学研究的范式
科学研究的范式是指科研共同体广泛采用的科研模式。在人类开展科学研究的漫长历程中,最本质性的变革莫过于范式变革。范式的变革必定会催生大量具体的重大科研成果,甚至推动生产力和生产关系的巨变。按照李国杰院士在《智能化科研(AI4R):第五科研范式》[3]一文中的归纳,在已有的四大科研范式(实验、理论、计算和数据)的基础上,第五范式——智能化科研正在出现。
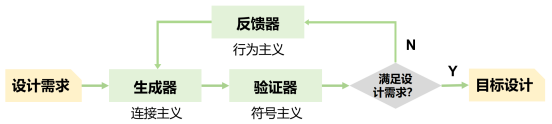
图1. 科学研究的五大范式
从某种意义上讲,第五范式的出现可能是科学史上最大的一次变革:科学研究不再以人为单一中心,而是以人-机为双中心。机器不再仅仅是人类科研的辅助工具,而是与人类形成了一种紧密协作的关系(或许类似于人类起导师的作用,机器起研究生的作用):人类负责提出科学问题、设定研究方向,机器提供建议;机器阅读文献、制定实验方案,人类进行修正和调整;具体实验的过程通过具身智能体来完成,人类给予指导;人类提出数据分析的大致思路,机器具体完成海量数据中的规律挖掘;人类编制论文的提纲,机器完成具体写作。
近来,孙凝晖院士提出了人-机双中心科研的OOHV流程。该流程是观察(Observe)、模拟(Orient)、猜想(Hypothesis)和实验(Verify)四个步骤的循环。每个步骤都可以在人类的指导下由人工智能来具体实施。这种人机协作不仅提升了科研效率,还拓展了科学研究的边界,使人类能够探索更复杂、更宏大、更交叉的科学问题。
当然,人-机双中心科研范式还没有在所有学科完全形成和全面应用。在某些环节,机器已经发挥了重要作用(如模拟);而在另一些环节,机器还未起到决定性作用(如在实体空间中做实验)。但即便如此,人工智能的部分赋能已经取得了非常显著的成效。据统计,2022年数学、物理和工程科学等领域的论文中,人工智能的渗透率已达到12.4%-15.3%[4]。
最为典型的例子当属 AlphaFold[5]。它基于深度学习算法,能够高精度预测超过100万个物种的2.14亿个蛋白质结构,解决了困扰结构生物学50年的难题。它让科研人员从繁琐的结构预测工作中解放出来,将更多精力投入到对生物学机制的深入理解和创新研究上。因此,AlphaFold获得2024年诺贝尔化学奖,可以说是实至名归。
AlphaFold不是孤例。在物理学领域,DeepMind和瑞士等离子体中心合作提出将强化学习用于优化托卡马克内部的核聚变等离子体控制[6];在天文学领域,人工智能已经应用在海量天文观测数据处理中,帮助人类发现新的天体和宇宙现象[7];在材料科学领域,人工智能已经应用在模拟和预测新型材料的性质中[8]。这些实例表明,人-机双中心的新范式正推动科学研究走向新的高度。因此,李国杰院士指出:“科研的智能化是一场科技上的革命。它带来的机遇和挑战将决定未来20年,中国在科技发展上是与国际先进水平拉大差距还是迎头赶上。”
PART TWO
处理器芯片研究尤其适合人工智能的介入
处理器芯片的研究属于高技术研究,相较数理化天地生等传统自然科学研究,一方面同属广义科学研究的一部分,另一方面又有很大不同。传统自然科学更注重发现新原理、新机制和新规律,而高技术研究更强调发明新方案、新工具和新产品。这种特殊性使得处理器芯片研究尤其适合人工智能的介入[9]。
处理器芯片研究要发现的目标非常明确清晰,就是要在工艺、成本、能耗等约束下,设计出速度尽可能高、应用尽可能广的芯片。其核心问题就是如何在庞大的高维空间中,找到精确满足复杂约束条件的最优解(或近似最优解)。通过机器学习方法,人工智能可以构建模型去自动探索不同的芯片架构、电路设计和工艺参数,快速筛选出速度最高的参数组合,从而显著提升设计效率和质量。处理器芯片研究领域丰富的数据资源(包括体系结构文档、逻辑设计代码、物理设计代码、性能测试结果等)又为机器学习模型的训练提供了高质量的数据支撑。
尤其值得指出的是,对处理器芯片研究的核心问题——如何在庞大的高维空间中搜索最优解,人工智能具备超越人类的潜力。人类大脑通常只能清晰分析由少数变量和公式组成的系统,难以直接搜索高维空间的理论最优解。因此传统芯片研究以人为中心,只能将高维空间分层分解为若干低维子问题,并在分解过程中基于人类直觉或者先验知识来降维和剪枝。例如,先将C语言级别的体系结构描述转换为RTL级的逻辑设计,再将RTL级的逻辑设计转换为基于布尔逻辑的网表,最后将网表转换为CMOS电路。
传统人为中心的芯片研究通过分层降维简化问题,不可避免地会扼杀许多潜在的优化机会,牺牲了全局最优性,使我们不可能触及芯片的理论最优解(“芯片之神”)。而人工智能技术可以在此展现出独特优势,突破人类经验局限,在海量晶体管组成的高维设计中捕捉人类难以察觉的优化路径。
这就好像在AlphaGo[10]出现之前,人类只能根据直觉和定势去搜索围棋中的“妙手”;但AlphaGo出现之后,我们才知道人类搜索出来的“妙手”距离人工智能水平相差有多远。AlphaGo甚至为我们打开了一扇全新的大门,使得我们终于有机会去一窥围棋的理论最优(“围棋之神”)。
PART THREE
基于大模型的处理器芯片研究
大模型是人工智能近七十年发展的最高成就,也是通向通用人工智能最具潜力的方向。因此,将大模型技术引入处理器芯片研究,是第五科研范式带来的一次彻底的革命。这场革命不仅体现在设计效率的显著提升,更在于它重新定义了芯片创新路径——通过构建覆盖算法、架构、电路到基础软件的人工智能自动设计体系,芯片设计得以突破传统人力密集型模式的限制,实现需求理解、架构探索、代码生成的全流程自动化。这将改变处理器芯片国际学术界的基本游戏规则。
更重要的是,这场革命对我国处理器芯片产业将带来前所未有的机遇。目前我国处理器芯片产业主要面临工艺、资源、生态三重壁垒的限制,而大模型等人工智能技术,可能会成为“破壁者”。面对工艺壁垒,人工智能可以通过搜索和生成高质量的芯片架构和电路实现,实现超越工艺代际的性能补偿。面对资源壁垒,人工智能替代人来设计处理器芯片,大幅降低人力和财力资源投入。面对生态壁垒,大模型通过实现跨指令集的程序自动转译甚至支持自然语言编程,打破指令集为核心建立起来的壁垒。
然而,处理器芯片研究所需要的大模型,绝不是“参谋将军”性质的常规大语言模型。仅仅能够回答一些处理器芯片相关的知识性问题,或为研究者提供模棱两可的建议,对学科和产业的发展意义有限。真正有价值的大模型,应能够从人类模糊、二义甚至不完整的需求规范出发,端到端地生成处理器芯片及其配套基础软件(包括操作系统、编译器和库)的代码。
这显然是一个极具挑战的任务。从实用角度看,处理器芯片的代码数通常以十万行计,而其功能正确性要求必须无限逼近100%,因为即使出错概率仅为十亿分之一,对于一个1GHz主频的单发射处理器芯片来说,每秒钟仍可能出错一次,这是绝对不可接受的。
由于硬件对规模和正确性的要求极高,处理器芯片大模型所面临的挑战,远比当前软件开发常用的Copilot[11]严峻得多。毕竟,软件开发者对Copilot要求的仅仅是以90%以上的正确率生成100行左右的代码。为此,处理器芯片全国重点实验室正在组织队伍开展攻关,力争取得突破。
PART FOUR
处理器芯片全国重点实验室的工作
作为全国首批20家标杆全国重点实验室之一,处理器芯片全国重点实验室(以下简称“实验室”)依托中国科学院计算技术研究所,是我国处理器芯片基础研究的“龙头”、“领头”和“源头”。实验室长期从事人工智能和处理器芯片的交叉研究,前期不仅研制了国际上首个深度学习处理器芯片寒武纪1号,也在国际上首次实现了完全由人工智能自动设计的通用处理器芯片启蒙1号。
在上述交叉研究过程中,我们发现,实现处理器芯片大模型不能仅依赖主流的连接主义的技术路线,而是需要融合连接主义大模型的可扩展性、符号主义形式化方法的精确性、行为主义反馈控制理论的收敛性等多种技术路线,取长补短,从而构建处理器芯片自动设计的技术体系。
基于人工智能奠基人Simon和Newell在1957年提出的“生成器-测试(Generator-Test)”通用问题求解框架[12],我们提出了一种处理器芯片自动设计新范式:即通过自动验证、自动生成与自动修复组成的反馈控制过程。在这一过程中,基于连接主义的大模型生成器负责生成尽可能满足设计需求的软硬件设计,基于符号主义的形式化验证器检查设计是否完全符合需求规范;若未能100%满足需求,行为主义控制反馈器则驱动生成器进行调试与修复,进入下一轮的“生成-验证-反馈”迭代。通过不断地反馈迭代,逐步修正大模型生成的解,最终在庞大高维空间中找到精确满足复杂约束的最优解。
需要指出的是,上述新的芯片自动设计体系,并不代表着人类的知识没有价值。例如,整个自动设计循环的最好的起点应当是人类前期设计的高质量开源处理器芯片,因为对超高维空间搜索问题,起点的质量对于最终找到的解的质量有着巨大的影响。在循环过程中,人类经验对于加速循环的收敛迭代,也会起到重要的作用。
基于上述芯片自动设计体系,实验室构建了贯穿计算机系统结构的垂直创新链条,全面覆盖从底层硬件到上层软件的四个关键层次(处理器芯片、操作系统、编译器和高性能库)的自动设计。
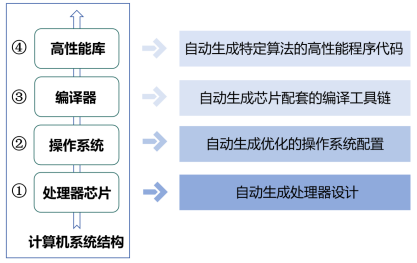
图3. 计算机系统四个关键层次自动设计的成果
1
自动生成处理器设计
我们提出了基于二元推测图(BSD)的自动电路设计基础模型,并成功实现了国际首个人工智能全自动设计的RISC-V处理器“启蒙1号”,和首个自动设计的超标量处理器“启蒙2号”。该工作发表于IJCAI2024[13],被Nature新闻评价为“对中国芯片的好消息”[14]。
2
自动生成优化的操作系统配置
我们和中科院软件所合作,提出了基于大模型的操作系统内核配置自动优化方法,通过“观察-剪枝-提议-执行-纠错”的反馈回路,大幅缩减搜索空间,仅需一天即可生成优化配置,性能最高提升25.6%,超越硬件厂商的手工优化水平。该工作发表于ICML2024[15]。
3
自动生成芯片配套的编译工具链
我们提出利用大语言模型直接构建端到端编译器的技术路线,通过程序的文法信息引导大模型思维链,并结合编译器领域知识,构建了专用大模型,成功完成了AnsiBench、CoreMark等真实代码编译验证。初步的成果发表在EMNLP2024[16]。
4
自动生成特定算法的高性能程序代码
我们提出了全球首个基于大模型的高性能矩阵乘法代码自动生成框架。该框架在RISC-V平台上的性能达到OpenBLAS的211%,在NVIDIA平台上的性能达到cuBLAS的115%,显著提升了生成代码的性能与开发效率。该工作发表于AAAI2025[17]。
PART FIVE
总结
目前,以大模型为代表的人工智能在处理器芯片设计中的应用已取得初步成果,但在性能、功耗和面积等多目标之间实现更优的平衡,仍需依赖人类专家的干预和优化。
处理器芯片全国重点实验室开设大模型研讨课,就是希望培养人工智能和处理器芯片交叉研究的“破壁者”。假以时日,破壁者将使人工智能在无人类干预的情况下,实现处理器芯片乃至整个计算机系统结构全自主设计与优化:人类提出高层次目标(如“设计一款能高效支持DeepSeek大模型的RISC-V处理器”),人工智能就可以在人类积累的先验知识基础之上,完成芯片、编译器、操作系统、高性能库的设计工作,并能自动建立评估、纠错、优化的完整闭环不断优化。最终,人工智能设计的芯片将超越人类顶尖设计师设计的芯片。对于结构复杂、组件繁多的通用CPU来说,人工智能的超越可能不是一蹴而就的事情;但是对领域专用的NPU和GPU,我相信人工智能的超越将会在不那么遥远的未来。
致谢:感谢处理器芯片全国重点实验室学术委员会主任孙凝晖院士对本文的指导。感谢高云凯、郭崎、张蕊、承书尧、文渊博、赵家程、李玲等同志对本文编写提供的帮助。
附:大模型研讨课内容
01
第一期:大模型概述与基础结构
赵永威从宏观角度回顾了大模型的发展历程,强调了大模型对计算机科学研究范式的深远影响,尤其是在自然语言处理(NLP)领域的创新性突破。
张蕊从技术层面详细讲解了大模型的基本结构原理,重点介绍了Transformer架构的核心设计及其在模型训练中的优势,为后续课程奠定了理论基础。
02
第二期:Transformer架构深入解析
张蕊进一步深入探讨了Transformer架构的三种流派(编码器-解码器、仅编码器、仅解码器),分析了不同流派的结构特点及其适用场景,特别是仅解码器架构成为主流的原因。她还结合实际案例,讲解了大模型结构设计中的难点,为后续课程的技术深入打下了坚实基础。
03
第三期:预训练与后训练
黄迪围绕大模型的训练流程,详细介绍了预训练的基础知识、尺度定律(Scaling Law)以及大模型在规模增长中表现出的涌现现象。他还讲解了后训练中的指令微调技术,特别是如何通过微调使模型更贴近实际应用需求,为参与者理解大模型的训练过程提供了清晰的框架。
04
第四期:强化学习在大模型中的应用
郭家明系统回顾了大模型的训练流程,并重点介绍了强化学习在后训练和微调中的应用。他详细讲解了人类偏好强化学习(RLHF)和AI反馈强化学习(RLAIF),以及自提升技术(如自对弈微调SPIN和自奖励机制),为大模型在缺乏人工反馈时的自主优化提供了创新思路。
05
第五期:大模型的推理机制
蓝思明围绕大语言模型的推理过程,深入讲解了解码策略(如贪心搜索、束搜索、采样和对比解码)以及提示词设计的重要性。他还介绍了上下文学习(ICL)和思维链推理(CoT)等技术,展示了如何通过优化推理机制提升大模型的实际应用性能。
06
第六期:长上下文推理与智能体
彭少辉探讨了长上下文推理的重要性,并介绍了提升长上下文推理能力的三种方法:位置外推、位置内插和提示压缩。他还深入讲解了大语言模型在智能体领域的应用,特别是ReAct框架如何结合内部推理与外部反馈,实现复杂任务的协同处理。
07
第七期:大模型变体
严彦阳介绍了混合专家模型(MoE)和视觉大模型。他详细讲解了混合专家模型的设计理念及其在多任务学习中的优势,并深入探讨了基于Transformer架构的视觉大模型和基于扩散模型的生成式模型,展示了这些模型在图像生成和编辑任务中的卓越表现。
08
第八期:多模态大模型
张子豪聚焦于多模态大模型,特别是视觉-语言模型(VLM)。他详细介绍了对比学习的基本原理及其在模型训练中的应用,并回顾了ALBEF、Flamingo、BLIP、LLaVA等前沿模型的设计思路与应用场景。此外,他还探讨了3D视觉技术的最新进展,特别是神经辐射场(NeRF)和文生三维技术(DreamFusion)的突破。
09
第九期:大模型系统软件
文渊博从系统软件的角度,深入讲解了大模型训练和推理的优化技术。他介绍了分布式训练策略(如数据并行)和计算效率优化方法(如FlashAttention),并详细分析了大模型推理中的键值缓存(KV Cache)优化和访存带宽瓶颈问题,为参与者提供了对底层技术的深刻理解。
10
第十期:大模型的典型应用
黄迪围绕代码大模型,回顾了代码生成技术的发展历程,并详细讲解了如何根据模型能力与代码数据规模进行微调,以实现智能化程序编写。
高云凯以具身智能为主题,介绍了大模型的分层架构与端到端架构的研究进展,展示了具身智能在机器人控制和交互任务中的应用潜力。
感谢大家对处理器芯片全国重点实验室大模型研讨课的关注和支持!诚邀您扫描下方二维码,填写调查问卷,提出您宝贵的意见!
引言:
[1]MIT Technology Review: Geoffrey Hinton tells us why he’s now scared of the tech he helped build.
https://www.technologyreview.com/2023/05/02/1072528/geoffrey-hinton-google-why-scared-ai/
[2]https://space.bilibili.com/494117284/lists/4188342?type=season
[3]李国杰. 智能化科研(AI4R):第五科研范式[J]. 中国科学院院刊, 2024,39(1):1-9.
[4]Hajkowicz S, Naughtin C, Sanderson C, et al. Artificial intelligence for science–Adoption trends and future development pathways[J]. 2022
[5]Jumper J, Evans R, Pritzel A, et al. Highly accurate protein structure prediction with AlphaFold[J]. nature, 2021, 596(7873): 583-589
[6]Degrave J, Felici F, Buchli J, et al. Magnetic control of tokamak plasmas through deep reinforcement learning[J]. Nature, 2022, 602(7897): 414-419
[7]Fluke C J, Jacobs C. Surveying the reach and maturity of machine learning and artificial intelligence in astronomy[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2020, 10(2): e1349
[8]Szymanski N J, Rendy B, Fei Y, et al. An autonomous laboratory for the accelerated synthesis of novel materials[J]. Nature, 2023, 624(7990): 86-91
[9]陈云霁, 郭崎. AI for Technology:技术智能在高技术领域的应用实践与未来展望[J]. 中国科学院院刊, 2024,39(1):34-40.
[10]Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. nature, 2016, 529(7587): 484-489
[11]Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021
[12]Simon H. & Newell A. Human problem solving. Prentice-Hall, 1972
[13]Cheng S, Jin P, Guo Q, et al. Automated CPU design by learning from input-output examples[C]//Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 2024: 3843-3853.
[14]https://www.nature.com/articles/d41586-024-01292-1
[15]Chen H, Wen Y, Cheng L, et al. AutoOS: Make Your OS More Powerful by Exploiting Large Language Models[C]//Forty-first International Conference on Machine Learning.
[16]Zhang S, Zhao J, Xia C, et al. Introducing Compiler Semantics into Large Language Models as Programming Language Translators: A Case Study of C to x86 Assembly[C]//Findings of the Association for Computational Linguistics: EMNLP 2024. 2024: 996-1011.
[17]Zhou Q, Wen Y, Chen R, et al. QiMeng-GEMM: Automatically Generating High-Performance Matrix Multiplication Code by Exploiting Large Language Models[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2025
处理器芯片全国重点实验室依托中国科学院计算技术研究所,是中国科学院批准正式启动建设的首批重点实验室之一,并被科技部遴选为首批 20个标杆全国重点实验室,2022年5月开始建设。实验室学术委员会主任为孙凝晖院士,实验室主任为陈云霁研究员。实验室近年来获得了处理器芯片领域首个国家自然科学奖等6项国家级科技奖励;在处理器芯片领域国际顶级会议发表论文的数量长期列居中国第一;在国际上成功开创了深度学习处理器等热门研究方向;直接或间接孵化了总市值数千亿元的国产处理器产业头部企业。





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000