
近日,第七十二届国际固态电路大会(ISSCC 2025)在美国旧金山隆重举行,该大会被誉为“芯片设计国际奥林匹克”。在本届大会上,北京大学共有15篇高水平论文(按第一单位统计)入选,成为此次国际上录用论文最多的单位。北京大学集成电路学院部分师生赴美参加了此次盛会,报告了各自方向的最新研究成果,并与国际同行进行深入的学术交流。
在此次盛会上,博士生叶思源、许欣航获得2024-2025年度SSCS国际固态电路协会博士成就奖(2024-2025 SSCS Predoctoral Achievement Award)。叶思源目前是博士五年级,研究方向是高速高精度ADC设计,已发表16篇高水平论文,包括3篇第一作者ISSCC论文和1篇第一作者JSSC论文;许欣航目前是博士三年级,研究方向是高精度模拟信号链和ADC设计,已发表15篇高水平论文,包括1篇第一作者ISSCC论文和多篇第一作者CICC、ESSCIRC等论文。叶思源的博士生导师为张兴教授、沈林晓研究员,许欣航的博士生导师为沈林晓研究员。
沈林晓研究员受ISSCC 2025 Forum 4 “Highlight of Data-Converter R&D in the Past 5-Years: A Comprehensive Overview”邀请,做题为“High-Performance Discrete-Time Amplifiers Utilizing Time-Varying Settling Processes”的邀请报告。沈林晓回顾了近年来应用于离散时间 ADC 的放大器结构,指出当前其发展方向正从时不变放大过程向时变放大过程转变。通过严谨的数学推导,沈林晓首次揭示了在时变放大过程中,实现最优噪声性能的带宽变化轨迹,即“最优建立过程(optimal settling process)”。此外,还结合多个电路案例展示了逼近最优建立过程的可行电路结构,为该领域研究提供重要参考。
 。
。
唐希源研究员担任会议TPC成员,并担任噪声整形与SAR ADC分论坛主席。此次的15篇高水平论文覆盖了模拟与混合、人工智能和数字加速、图像、有线通信等领域,具体工作介绍如下:
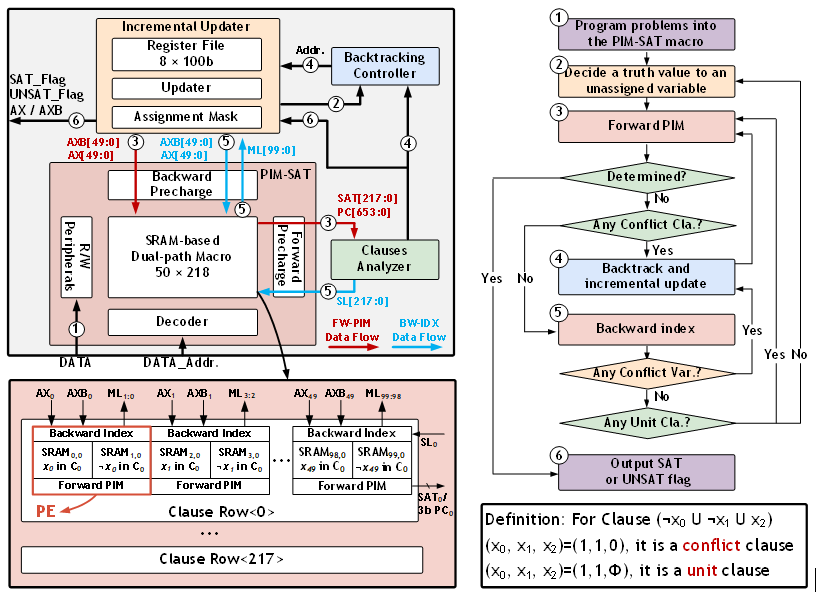
工作1:可满足性求解器
现有ASIC可满足性求解方案均采用非完备性分析,虽能实现快速求解,却无法避免解空间的遗漏风险。在理论证明层面上,这类非完备方法可能因corner case的缺失导致验证结果不可靠;在工程实践中,其随机收敛特性更难以满足形式化验证、自动推理等场景的确定性需求。
为此,北京大学团队提出首款支持完备性验证的K-SAT专用集成电路求解器SKADI,通过硬件架构创新确保解空间的穷尽性探索。提出的SKADI架构具有两个核心特征,分别是dual-path SRAM-based macro单元与incremental updating策略:前者通过前向计算和后向检索实现了高效的子句-文字双向推导,而后者采用路径回溯压缩技术达成历史赋值信息核心节点的线性存储。在28nm工艺节点上,该设计以0.2mm²的核心面积实现硬件级完备性验证,针对uf50-218标准算例达成平均17.1μs的求解时间,运行功耗稳定在3.39mW。
该成果以《SKADI: A 28nm Complete K-SAT Solver Featuring Dual-path SRAM-based Macro and Incremental Update with 100% Solvability》为题,发表于设计技术优化和数字加速器(Design-Technology Optimization and Digital Accelerators)分会场,博士生吴子涵为第一作者,通讯作者为唐希源、王源。
工作2.基于存算一体的多内容生成扩散模型加速器芯片
扩散模型在图像、三维模型和视频等视觉内容生成任务中表现出优异性能,但在部署时面临严峻的硬件挑战。例如,在A100 GPU上生成24帧视频需要约70s。由于存储和计算需求不均衡,模型部署中硬件利用率严重降低。存内计算宏单元数据复用能力有限、频繁权重更新导致硬件能效下降。此外,三维和视频内容生成算法引入的一致性计算需求进一步增大了计算强度。
针对以上问题,北京大学团队提出了一种基于存内计算的多内容生成扩散模型加速器芯片。通过带宽感知的存储切分,根据工作负载动态调整硬件资源分配,提高系统利用率。采用位线切割和查找表-旁路加法器来提高宏单元计算能效,并结合权重更新调度单元减少硬件访存开销。团队还开发了多视图一致性调度单元,以优化冗余计算,进一步提高硬件性能。该芯片实现了60.81TFLOPS/W的峰值系统能效,与已有的扩散模型加速器相比,取得了1.4倍的性能提升和1.5倍的能效提升,达到了国际领先水平。
该工作以“A 22nm 60.81TFLOPS/W Diffusion Accelerator with Bandwidth-Aware Memory Partition and BL-Segmented Compute-in-Memory for Efficient Multi-Task Content Generation”为题发表,博士生景亦奇为第一作者,通讯作者为贾天宇、叶乐。
工作3:超低功耗语音活动检测检测芯片
该工作面向边缘AIoT设备应用,针对语音活动检测(VAD)系统在功耗、噪声鲁棒性及准确性方面的综合性能瓶颈,设计并实现了一款基于信息感知数据压缩与神经形态时空特征提取的超低功耗VAD芯片,突破了传统方案中功耗与精度无法折中的技术局限。
北京大学团队提出了一种全新的语音活动检测系统,该系统创新性地将信息感知数据压缩(IADC)与神经时空特征提取(NSTFE)相结合,通过仅提取语音中的关键极值点,将原始语音信号高效压缩为5位地址事件表示,进而触发后续的时空特征提取与神经网络推理。与传统采用低噪放大器和固定特征提取结构的方案相比,本设计利用模拟域的极值压缩电路配合8位SAR ADC,仅在检测到极值时启动转换,大幅降低了功耗;同时,NSTFE采用异步握手与共享存储计算资源,实现了低功耗神经网运算,在保证准确特征提取的同时,有效缩小了芯片规模,兼顾了识别准确率与系统能耗。
基于以上创新技术,研制了超低功耗的语音活动检测芯片,在55nm工艺下,芯片的核心面积仅有0.22mm2,功耗仅为161nW,在0dB、5dB、10dB和15dB SNR下分别达到84%、90%、94%和98%的识别率,在极低功耗的情况下实现了远超同类工作的识别精度。该芯片具备高准确率,高能效等优势,可应用于边缘端AI设备。
该工作以《A 0.22mm2 161nW Noise-Robust Voice-Activity Detection Using Information-Aware Data Compression and Neuromorphic Spatial-Temporal Feature Extraction》为题,发表于低功耗和低温计算芯片(Session 13 Cool Computation Circuits)分会场,共同第一作者为博士生刘影、李杰和硕士生张麒宁,通讯作者为沈林晓、王志轩。
工作4:高精度电容读出芯片
电容传感器由于其结构简单、成本低廉、性能卓越等优势被广泛应用,包含无人机在内的一些需要实时监测的应用场景对电容传感器读出电路提出了低延迟、高精度、高能效的要求。
北京大学团队研制了一款增量型缩放式电容-数字转换器芯片,该芯片采用基于斩波的采样噪声消除技术,低成本地解决了采样噪声问题;提出了一种适用于压控振荡器的相位域前馈补偿方法,充分利用离散时间Delta-Sigma调制器的时序特点,保证环路的稳定;同时,该芯片还利用自适应偏置浮动反相放大器构建第一级积分器,进一步提高了系统的能效。
基于上述技术研制了一款基于28nm CMOS工艺的电容-数字转换器芯片,在0-1.2pF的测量范围以及10.4μs的测量时间下,实现了93.8dB的信噪比和185.2dB FoMs的能效,达到了国际领先水平。
该工作以“A 185.2dB-FoMs 8.7-aFrms Zoomed Capacitance-to-Digital Converter with Chopping-Based kT/C Noise Cancellation and Add-Then-Subtract Phase-Domain Lead-Compensation Technique”为题发表,第一作者是博士生李秉芮,通讯作者为唐希源。
工作5:采用增益嵌入式自举采样器的高能效ΔΣ模数转换器芯片
该工作面向高精度传感器测量与工业物联网应用,针对高精度ΔΣ调制器输入驱动功耗高、线性度受限以及传统架构中噪声与回踢干扰严重等难题,提出了一种增益嵌入式自举采样器与分段动态元件匹配技术相结合的高能效模数转换器架构,在单电源域下实现了超低驱动功耗、高线性度输入接口与免校准高精度量化性能。
针对上述挑战,北京大学团队提出以下核心技术突破:
(1)首创增益嵌入式自举采样器输入级架构,通过双CDAC结构将PMOS晶体管栅极与漏极同时接入反馈信号,形成Gm-C增益级实现信号残差提取与放大一体化。该技术使输入驱动仅需处理噪声级残差信号,驱动电流需求较传统DT/CT架构降低两个数量级,同时通过源端电位跟随机制保证了轨到轨线性度。
(2)利用伪伪差分(PPD)工作模式,通过时序控制实现闪烁噪声抑制与CDAC的kT/C噪声抵消。在放大阶段保留复位相位的噪声分量,利用差分路径噪声相关特性实现有效噪声消除。
(3)利用分段动态元件匹配(DEM)技术,将8位DAC拆分为5+3位分段结构。采用数字ΔΣ调制对LSB段代码进行高通整形,结合MSB段延迟加权平均(DWA)算法,在硬件复杂度指数增长趋势下实现4倍能效提升,有效将分段失配误差抑制40dB以上。
(4)创新数字斜率粗量化ADC架构,通过5b-3b分段CDAC与预测式逐次逼近算法协同设计,在125倍过采样率下实现每周期小于4次比较的高效量化。该设计无缝对接分段DEM系统,显著降低组合逻辑复杂度。
基于上述创新技术研制了一款55nm CMOS工艺实现的高精度ΔΣ模数转换器芯片,测试结果显示:在1MHz时钟频率、4kHz信号带宽下,该芯片在无校准条件下实现了99.6dB SNDR与102.0dB动态范围,整体功耗仅为12.2μW,创造了184.8dB FOMSNDR与187.2dB FOMDR的性能纪录。其输入驱动电流需求较传统架构降低98%,为前端缓冲器节省了可观的系统级功耗。温度特性测试表明,芯片在-40°C至85°C范围内性能波动小于1dB,展现出优异的工艺鲁棒性。性能对比显示,本工作在所有kHz级高精度ADC中达到最优能效指标。
该成果以《采用增益嵌入式自举采样器实现184.8dB FOMSNDR的高能效ΔΣ模数转换器芯片》(A 12.2uW 99.6dB-SNDR 184.8dB-FOMs DT Zoom PPD ΔΣM with Gain-Embedded Bootstrapped Sampler)为题,入选噪声整形与逐次逼近型模数转换器分会场(Session 18: Noise-Shaping and SAR-based ADC),第一作者为博士生栾耀晖,通讯作者为沈林晓。
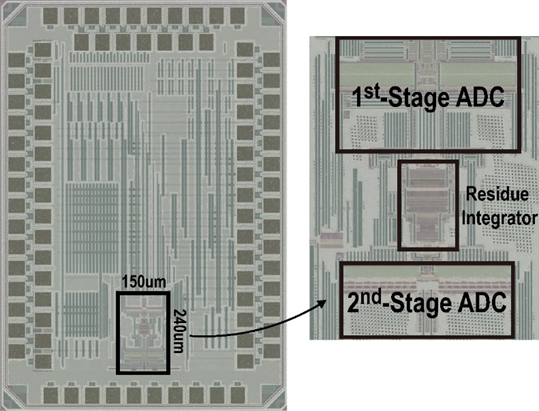
工作6:高精度高能效免校准流水线-逐次逼近型模数转换器芯片
该工作面向物联网传感器应用,针对不断提升的高能效模数转换器需求,以及传感器链条中失配误差和增益误差引入的额外校准代价,提出了一种新型的高能效免校准的流水线-逐次逼近型模数转换器设计,实现了温度、工艺和电压涨落下的免校准设计,并结合高能效的动态积分器实现了低成本的噪声整形,进一步提高了精度。
针对以上问题,北京大学团队首次提出了失配误差和增益误差的归一化技术,将级间增益误差和第二级模数转换器的失配误差结合为整体进行失配误差整形,从而突破了原有技术中失配误差整形只适用于单级模数转换器的限制,使得流水线型模数转换器中的失配和增益误差能被同时搬移到有效信号带宽之外,使得该电路不需要在实际测试过程中进行任何校准。针对失配误差整形技术可能导致的饱和及基准缺失问题,引入了反馈电容来抵消部分补偿电压,在避免了饱和的同时可以提供失配误差传递的通道,实现整形基准。此外,由于该技术使得第二级电容阵列不会在放大时进行复位,会天然的保留上级板的余量电压,因此本工作提出了基于级间积分器的天然噪声整形技术。利用级间积分器保护第二级电容阵列保存的余量信息,从而实现误差反馈型噪声整形(Error-feedback Noise-shaping),提高整体精度。
基于上述理念和技术研制了一款基于55nm CMOS工艺的高能效模数转换器芯片,该技术在20MHz采样率下实现了93.3dB SNDR的精度和4.71uW的功耗,并且测试过程中不需要对级间增益和电容权重进行额外校准。该成果首次实现了多级模数转换器的失配误差整形,并且用单比特电容反馈实现了增益误差整形,不带来额外的硬件代价。在所有失配误差整形模数转换器中实现了最高的带宽和动态范围,并在所有增益误差整形架构中实现了完全免校准和最高的增益误差容忍范围(-33%~+50%)。
该工作以《A 93.3 dB SNDR, 180.4dB FoMs Calibration-Free Noise-Shaping Pipelined-SAR ADC with Cross-Stage Gain-Mismatch Error Shaping Technique and Negative-R-Assisted Residue Integrator》为题,作为模数转换器方向的亮点论文(highlight),发表于噪声整形和逐次逼近型模数转换器领域(Session 18 Noise-shaping and SAR-based ADC)分会场,第一作者为博士生高继航,通讯作者为沈林晓。
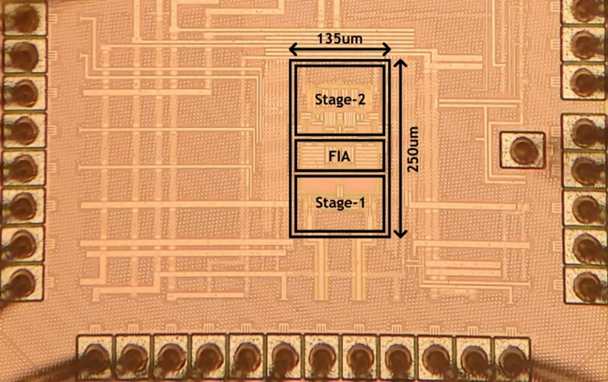
工作7:高精度低延迟模数转换器芯片
模数转换器在信号链中起着至关重要的桥梁作用,连接着现实世界与数字世界。在许多新兴的物联网应用中,如语音识别和声波定位等,模数转换器需要具备高精度,以准确捕捉微小幅度的输入信号;高能效,以延长设备的电池续航;中等带宽,以实现对信号变化的快速响应。此外,模数转换器还应具备易于驱动的特性,以便在复杂的信号链中进行集成。
北京大学团队设计了一款增量型流水线式噪声整形模数转换器芯片来满足上述需求,其中包含一种高效的采样噪声抵消技术,该技术以极低的放大器功耗和时间开销大幅提升了模数转换器的采样精度,从而可以显著减小模数转换器的采样电容值,不仅节省了电容的面积和电容切换的功耗,还使得模数转换器容易被驱动和在信号链中集成。此外,在该款芯片中,还设计了乒乓采样噪声抵消电容来进一步加快转换速度,提出了两步式转换来增强级间放大器的线性度,采用了可变阶数环路滤波器来提升模数转换器的能效等。
基于上述创新技术,基于28nm CMOS工艺实现的增量型流水线式噪声整形模数转换器芯片在采样电容仅为0.8pF的情况下同时达成了高精度(92.5dB SNDR)、高转换速度(1.6MS/s)、高能量效率(184.8dB FoMs)。与其他已发表的高精度增量型模数转换器相比,该芯片取得了最快的转换速度和最高的能效。同时,该款模数转换器芯片容易被驱动的特点也使得其不依赖于高功耗强驱动能力的模数转换器驱动器,从而有效降低了信号链模拟前端的功耗开销和设计复杂度,极大地提升了其在多种物联网场景中的应用适配性。
该工作以《A 184.8dB-FoMs 1.6MS/s Incremental Noise-Shaping Pipeline ADC with Single-Amplification-Based kT/C Noise Cancellation Technique》为题发表,第一作者为博士生王宗楠,通讯作者为唐希源。
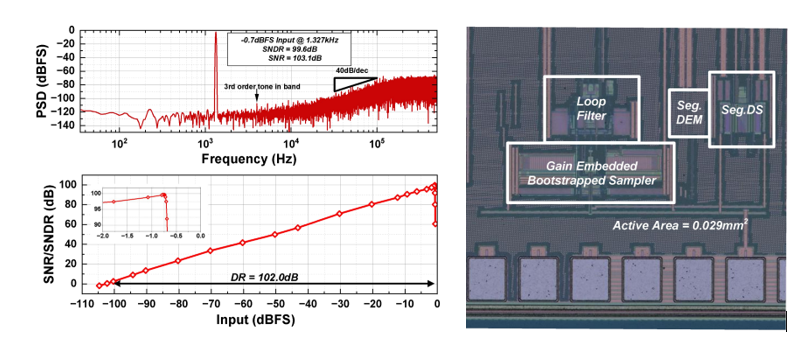
工作8:高能效轨到轨高线性度噪声整形逐次逼近模数转换器系统芯片
该工作面向物联网,传感器前端与工程测量等应用,针对不断提升的高精度高能效信号链系统的要求,提出并实现了一款高精度,高能效的轨到轨噪声整形-逐次逼近型模数转换器系统,在单一电源电压域下实现轨到轨高线性度高精度的信号放大与量化,同时在系统层级实现了很高的能效和面积效率,突破了传统模拟信号链架构中能效和面积两大瓶颈。
针对以上瓶颈,北京大学团队在模数转换器前级驱动放大器和模数转换器两个方面提出解决方案:提出了基于连续时间的相关电平抬升技术,创新性地利用开关电容结构显著降低采样时期连续时间放大器的输出摆幅,从而实现了轨到轨高线性度的输出信号;采用了预放大器复用的采样噪声消除技术,从而能显著降低采样电容大小,减小前级驱动放大器的驱动压力。此外,复用的预放大器提供的电压增益也有效抑制了后级环路滤波器的噪声,从而有助于实现一个紧凑型高能效的环路滤波器电路。基于上述技术,本工作在系统层级实现了前级驱动和模数转换器的能效协同优化。
基于上述架构和电路层面的创新,研制了一款基于55nm CMOS工艺的高精度高能效的模数转换器系统芯片。在55nm工艺下,该芯片在40MS/s的采样率下实现了82.9dB SNDR的精度,105.4dB SFDR的线性度和1.12mW的功耗,在所有采用轨到轨驱动的模数转换器系统中达到了最高的轨到轨信号线性度(105.4dB SFDR)和有竞争力的能效(176.3dB FoMs)。该电路具有高精度(>80dB),高线性度(>100dB),中等带宽(~MHz),高能效等特点,可广泛应用于物联网,传感器前端与工程测量等应用中。
该工作以“A Rail-to-Rail 3rd-Order Noise-Shaping SAR ADC Achieving 105.4dB SFDR with Integrated Input Buffer Using Continuous-Time Correlated Level Shifting”)为题发表于噪声整形和逐次逼近型模数转换器领域(Session18 Noise Shaping and SAR based ADC)分会场,第一作者为博士生叶思源,通讯作者为沈林晓。
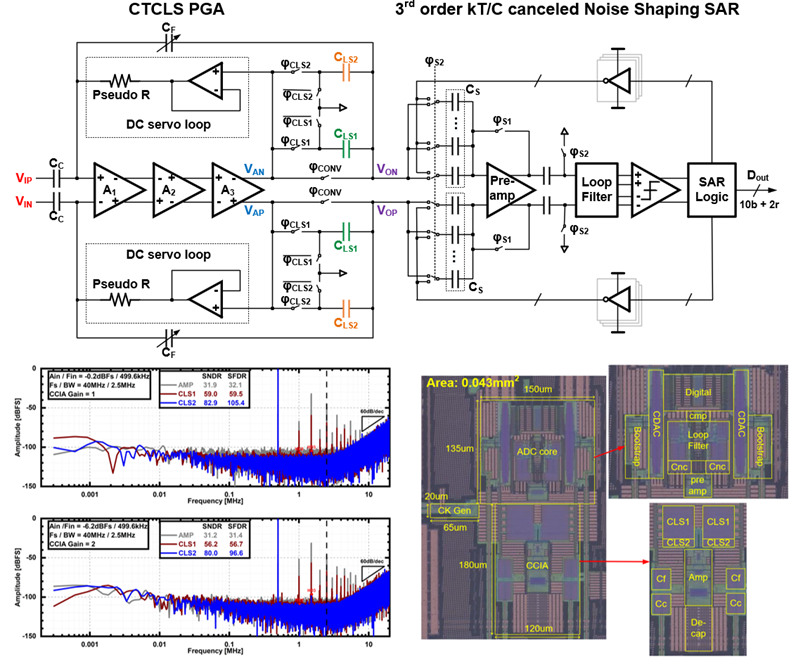
工作9:易驱动的轨到轨高能效流水线-逐次逼近型模数转换器芯片
该工作面向通信、医学成像等需求,针对不断提升的高能效模数转换器的需求,提出并实现了一款高精度、高能效的16MS/s流水线-逐次逼近型模数转换器系统(Pipelined-SAR ADC)。该系统采用了分裂粗细输入缓冲器采样方案,并提出了一种快速且具有PVT鲁棒性的后台级间增益校准技术。通过这种方案,系统能够实现轨到轨高线性度的信号采样与量化,并在系统层面显著提高了能效,突破了传统架构中的能效瓶颈。
针对以上问题,北京大学团队提出了解决方案,针对流水线-逐次逼近型模数转换器的输入缓冲器和ADC本身提出了创新设计。输入缓冲器方面,本工作引入了分裂粗细输入缓冲器采样方案,通过将输入缓冲器分为粗缓冲和细缓冲两个部分,优化了能效。粗缓冲采用低功耗推挽源跟随器,用于快速完成初始信号的建立,而细缓冲采用高功率的共源共栅推挽源跟随器,保证在跟踪阶段具有高线性度和低噪声。此外,针对级间增益校准,本工作提出了失调电压消除和概率控制的技术,有效地解决了PN注入式校准中常见的难题,确保了校准的速度与稳定性。
基于上述创新技术研制了一款基于22nm CMOS工艺的高精度高能效模数转换器芯片。该芯片在16MS/s的采样率下实现了79.4dB的SNDR、99.4dB的SFDR以及1.62mW的功耗,具有高精度、高线性度等优良特性,可广泛应用于通信、医学成像与工程测量等领域。得益于该技术,系统的能量效率(FoMs值)达到了176.3dB,FoMw值为13.3fJ/conv.-step,表现出极高的能效。
该工作以“An Easy-Drive 16MS/s Pipelined-SAR ADC Using Split Coarse-Fine Input Buffer Sampling Scheme and Fast-Robust Background Inter-Stage Gain Calibration”为题,发表于噪声整形和逐次逼近型模数转换器领域(Session18 Noise Shaping and SAR based ADC)分会场,第一作者为博士生陈卓毅,通讯作者为沈林晓。
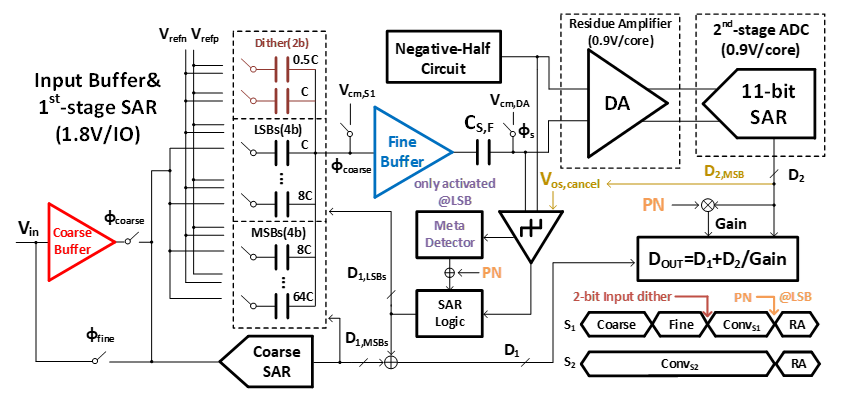

工作10:采用光电流自驱动的像素级电流相位型ADC的红外焦平面成像芯片
该工作面向高性能长波红外探测和成像应用,针对传统长波红外动态范围受限、功耗高以及传输串扰严重等难题,提出了光电流自驱动调制器、相位抽取电路和异步格雷码计数器结合的高动态、高能效比20bit像素级ADC架构,以及低摆幅、低串扰的传输架构,实现了低功耗、低噪声等效温差(NETD)、高动态范围的红外焦平面成像芯片。
针对上述挑战,北京大学团队提出光电流驱动振荡器作为调制器,实现电流-相位转化,该调制器完全由光电流进行供电,能够极大节省功耗开销;像素内加入相位重建和子相位提取电路,降低量化噪声的同时提升暗光条件下的成像能力;像素内集成了20bit的相位积分器,实现高动态范围探测;读出结构采用一种低摆幅数据传输电路,降低传输过程中的串扰,同时降低了64%的传输功耗。
基于上述创新技术,研制了一款180nm CMOS工艺实现的320×256规模读出电路芯片,与量子阱传感器阵列进行三维键合,实现了异质三维堆叠的红外焦平面成像芯片。测试结果显示:该芯片在40K低温工作环境下,达到120.4dB动态范围,最高109dB的SNR以及2.2mK的NETD,整体功耗在典型目标下仅为6.9mW(较国内外同类芯片低一个数量级),该芯片在极高的温度动态范围内具有连续高精度细节,在高性能图像传感器领域达到最优能效指标。
该成果以“A 320×256 6.9mW 2.2mK-NETD 120.4dB-DR LW-IRFPA with Pixel-Paralleled Light-Driven 20b Current-to-Phase ADC”)为题,发表于图像与显示分会(Session 6: IMAGERS AND DISPLAYS),第一作者为博士生卓毅,通讯作者为张雅聪、鲁文高。
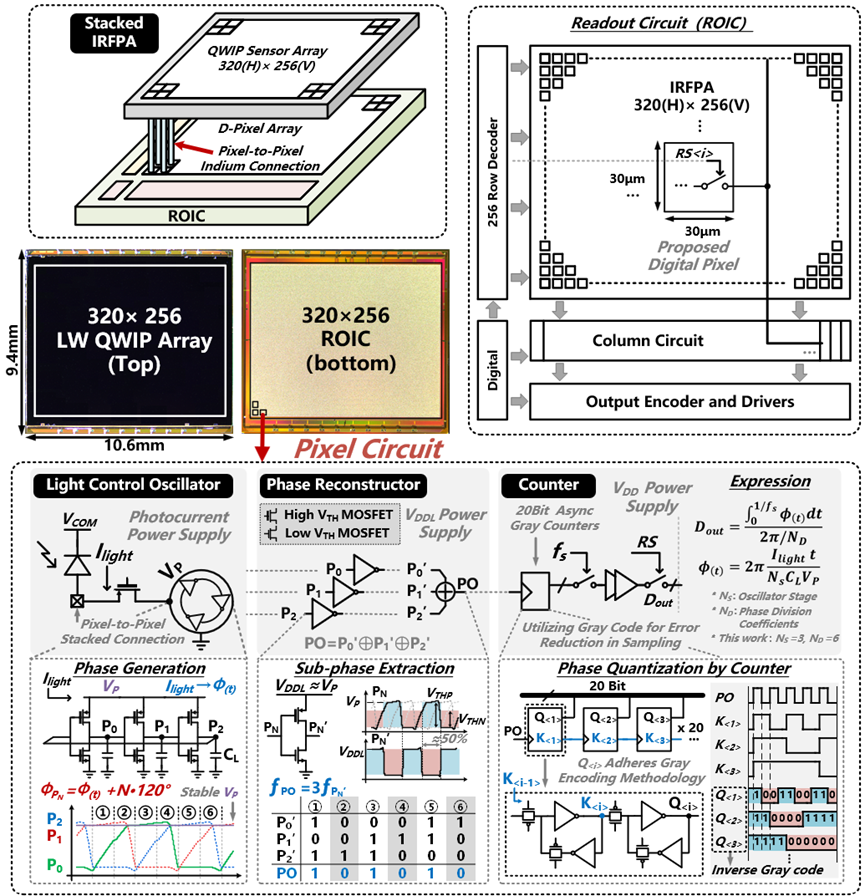
工作11:突发模式快速响应接收机芯片
家庭宽带光纤入户依赖于无源光网络技术。4K超高清视频,云存储等技术的普及推动宽带速率需求快速上升,也使得无源光网络迈入50G速率时代。现有无源光网络接收机芯片无法支持在大衰减,强噪声的条件下实现对突发信号的快速响应接收,无法适应50G无源光网络接收要求。
针对这一问题,北京大学团队研制了一款50Gb/s NRZ突发模式快速响应接收机芯片。提出一种波特率快速锁定CDR算法,抑制噪声影响的同时使得接收机能够实现多个均衡器抽头,以应对50G无源光网络中的复杂衰减;研究信号边沿均衡技术,提升大衰减下快速锁定CDR相位锁定精度,减小锁定时间。此外,团队还提出一种新型数字可控电流源电路,减小寄生电容负载;设计了一种并行式浮动抽头选择电路,降低寄存器工作频率,减小电路功耗。基于以上技术,团队采用28nm CMOS工艺完成了流片验证,并进行了性能测试和汇报。接收机灵敏度达-24dBm,弱光强下快速锁定时间仅15ns,是世界首款支持50G突发接收的无源光网络专用芯片,功耗仅需已有数字方案的1/10,达到了国际领先水平。
该工作以“A 50Gb/s Burst-Mode NRZ Receiver with 5-Tap FFE, 7-Tap DFE and 15ns Lock Time in 28nm CMOS for Symmetric 50G-PON”为题发表,共同第一作者为博士生张泊洋、叶天辰,通讯作者为盖伟新。
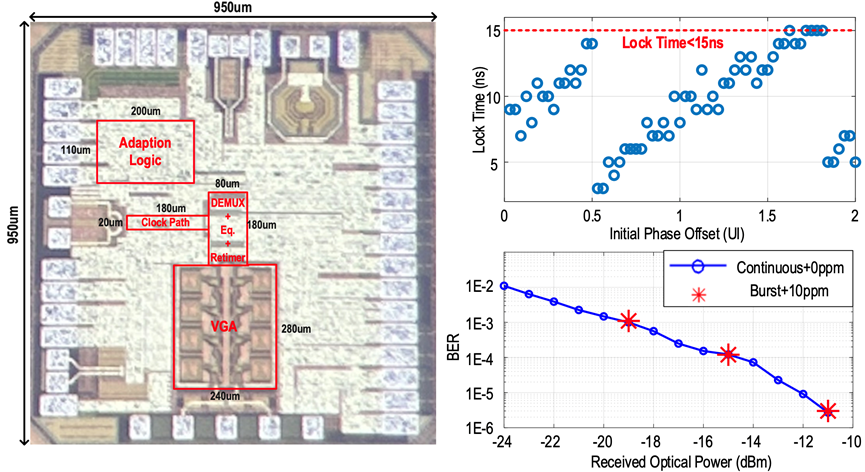
工作12:高密度无源信道信号完整性测试芯片
随着网络带宽需求的不断增长,以太网交换机和高性能计算机内的通道密度显著增加,印制电路板走线和同轴电缆等无源信道的信号完整性问题也愈发严重。因此,低功耗且高效的信号完整性测量对于检测通信设备中的缺陷至关重要。传统意义上的信号完整性测试仪器如矢量网络分析仪和采样示波器功耗高、价格昂贵,且由于端口数量有限,效率较低。
针对这一问题,北京大学团队研制了一款高密度无源信道信号完整性测试芯片。提出一种可编码边沿脉冲发送技术以及基于时钟门控电路的多路复用器,有效抑制发送机输出纹波的同时提高了阶跃信号高频部分的能量分布,突破了传统时域网络测量技术高频段低信噪比对测量带宽的限制。此外,团队还提出了一种基于时钟升压电路和密勒电容效应的采样保持单元,保证高带宽高线性度的同时,有效减少了沟道漏电带来的保持误差。基于以上技术,团队采用28nm CMOS工艺完成了流片验证,并进行了性能测试和汇报。芯片拥有DC到40GHz的测量带宽,单测试端口功耗仅99.5mW,阻抗测量误差达到1.2%以下,插入损耗测量误差控制在6.5%以下,是世界首款采用时域网络测量技术的无源信道测试芯片,同时也是世界首款基于CMOS工艺的信道测试芯片。
该工作以“A 99.5mW/port DC-to-40GHz Integrated Channel Analyzer for High-Density Signal Integrity Measurement in 28nm CMOS”为题发表,共同第一作者为博士生吴广栋、李元梁和博士毕业生叶秉奕,通讯作者为盖伟新。
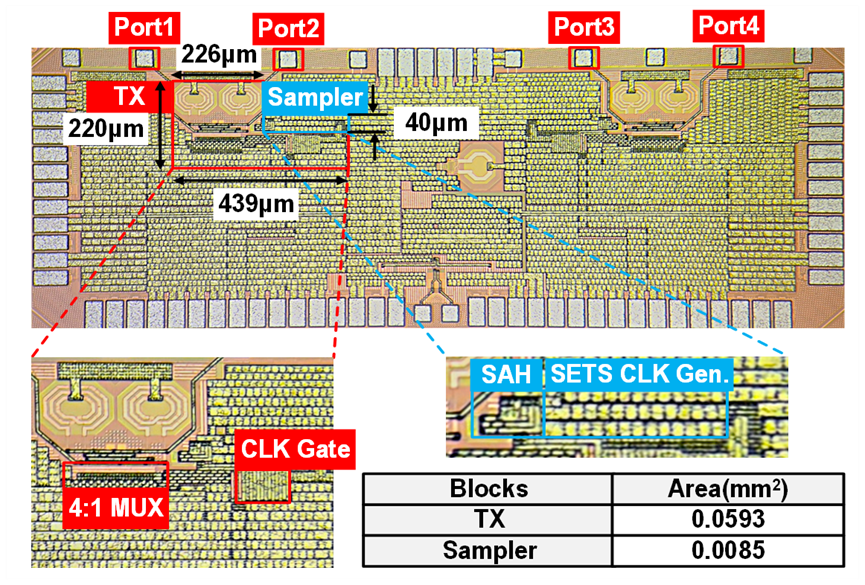
工作13:224Gb/s极短距接收机芯片
随着半导体行业进入后摩尔时代,多芯片共封装成为继续提升集成电路性能的重要路径之一。与传统的板级互联相比,封装内部互联的距离更短、密度更高,但严格的功耗和面积要求限制了速率进一步提升。
针对该问题,北京大学团队提出了一种多单元CTLE电路,可以同时取得较高的增益和较小的调节步长,实现了高于59GHz的模拟带宽;此外,通过提高CTLE的峰值频率减小了群延迟的波动,降低对FFE抽头数量的要求,仅使用三抽头就能在13.6dB衰减信道下实现8.1e-7的误码率;还提出了一种基于相位插值器及非线性预失真的八相位时钟产生电路,在不使用注入锁定环形振荡器的条件下,产生八相位14GHz时钟,相位误差低于3.6度。基于上述技术,研究团队使用12nm工艺流片验证了一款224Gb/s极短距接收机芯片,实现了当前模拟接收机的最高速率;能耗仅为1.11pJ/b,优于3nm工艺的数字接收机。
该工作以"A 1.11pJ/b 224Gb/s XSR Receiver with Slice-Based CTLE and PI-Based Clock Generator in 12nm CMOS"为题,发表于超高速有线通信(Session 7: Ultra-High-Speed Wireline)分会场,第一作者为博士毕业生叶秉奕,通讯作者为盖伟新。
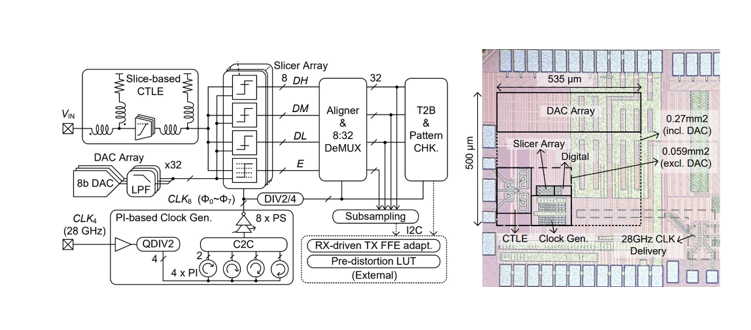
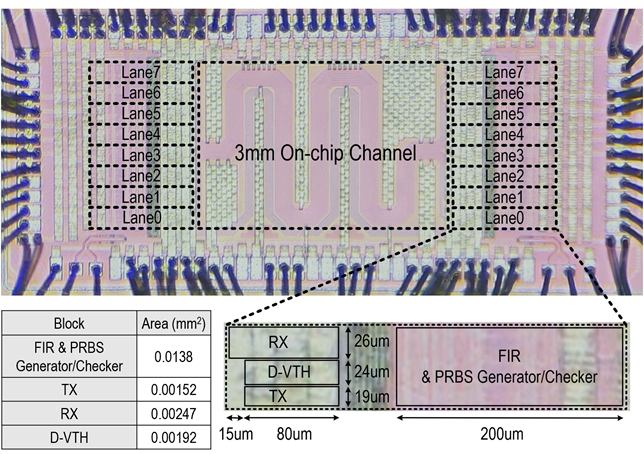
工作14:面向芯粒集成的全双工收发机芯片
人工智能、高性能计算的发展对芯粒间互连接口的速率、带宽密度和误码率提出了更高的要求。PAM等高阶调制方式在提升接口速率的同时带来较大的信噪比损失,加之芯粒高密度集成下的严重串扰,难以实现极低的误码率、无法满足芯粒间互连的要求。
针对这一问题,北京大学团队研制了一款单通道64Gb/s的全双工收发机芯片,采用无屏蔽互连信道,将带宽密度提升至10.5Tb/s/mm。研究容性、感性耦合平衡技术,设计了3mm长的片上互连信道,消除远端串扰对信号接收的影响;研究动态阈值判决技术,利用比较过程中信号相减的特性,以较低的功耗实现全双工信号解耦、近端串扰与反射消除;研究时钟同步技术,利用驻波实现高速时钟的同步,并设计分频器重置信号传递链路,实现了分频时钟的同步,以此提升近端串扰的消除精度。团队采用28nm CMOS工艺完成了流片验证,并进行了性能测试和汇报。收发机误码率可以达到1e-16以下,串扰导致抖动的消除率达到89.6%,达到了国际领先水平。
该工作以“A 64Gb/s/wire 10.5Tb/s/mm/layer Single-Ended Simultaneous Bi-Directional Transceiver with Echo and Crosstalk Cancellation for a Die-to-Die Interface in 28nm CMOS”为题发表,第一作者为博士生王知非,通讯作者为盖伟新。
工作15:Nebula——用于三维点云分析的高能效神经网络加速器
点云是由激光雷达、深度相机等新型传感器采集到的数据格式,由于只抓取物体轮廓上的点,因此相比于传统的图像和视频,点云可以用更少的数据量实现更高的分辨率,在无人驾驶、机器人、无人机、AR/VR等领域有着巨大的应用前景。深度学习技术(点云神经网络)也开始广泛应用于点云的分析和处理。此次信息工程学院的研究工作旨在解决当前点云神经网络计算复杂度高、并行性差以及频繁的不规则外部内存访问,导致在硬件上部署点云神经网络面临的巨大挑战。该研究工作开发了一种用于三维点云分析的高能效神经网络加速器 Nebula,采用基于八叉树的自适应分块、基于采样的多级跳过以及基于流水线的分块延迟聚合,分别解决了点云神经网络中最远点采样的串行计算带来的高延迟、大量的冗余计算以及频繁的非规则访存。该工作采用了28纳米工艺进行了流片验证,芯片的峰值能效达到了109.8 TOPS/W(20 MHz,INT8),峰值帧率和峰值面积效率分别达到了5263 fps和5.6 TOPS/mm2(200 MHz,INT8),远超当前的国际领先水平。此项研究工作为后续在自动驾驶、机器人等新兴领域的应用提供了广泛的思路。
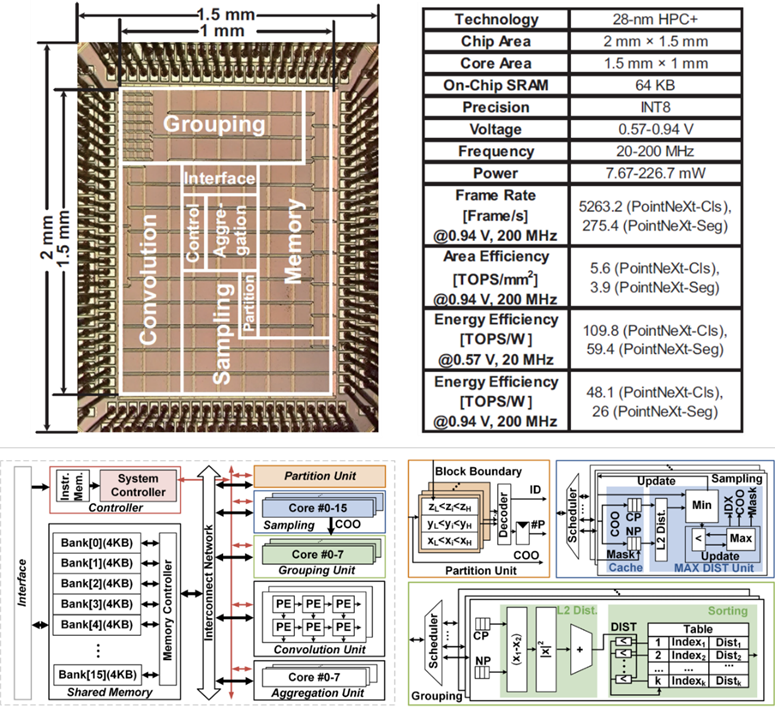
该工作由广东省存算一体芯片重点实验室杨玉超教授、焦海龙长聘副教授课题组与李革教授课题组、瑞为技术合作完成,以“A 28nm 109.8TOPS/W 3D PNN Accelerator Featuring Adaptive Partition, Multi-Skipping, and Block-Wise Aggregation”为题发表,北京大学深圳研究生院信息工程学院博士周长春为第一作者,杨玉超、焦海龙为共同通讯作者,是北京大学深圳研究生院首次在ISSCC发表论文。
会后,为深化母校与校友的联系纽带,北京大学集成电路学院联合当地北大北加州校友会,共同举办校友交流和聚会活动。活动上,校友会负责人向与会师生和校友们系统介绍了当地校友会的组织结构、发展规模及日常活动开展情况。参会师生代表转达了学院对校友们的亲切问候,教师代表贾天宇研究员向校友们介绍了学院最新的进展和学院建设情况。在自由交流环节中,与会师生和校友们展开了热烈的讨论。









