

【编者按】摩尔线程科研团队发布研究成果《Round Attention:以轮次块稀疏性开辟多轮对话优化新范式》,该方法端到端延迟低于现在主流的Flash Attention推理引擎,kv-cache 显存占用节省55%到82% 。
近年来,大型语言模型的进步推动了语言模型服务在日常问题解决任务中的广泛应用。然而,长时间的交互暴露出两大显著挑战:首先,上下文长度的快速扩张因自注意力机制的平方级复杂度而导致巨大的计算开销;其次,尽管键值( KV )缓存技术能缓解冗余计算,但其显著增加的 GPU 内存需求导致推理批处理规模受限及 GPU 利用率低下。摩尔线程提出 Round Attention 用于解决这些问题。
01 论文主要贡献
▼ 以轮次为分析单元研究 Attention 规律:Round Attention 专为多轮对话场景推理需求设计,以轮次为自然边界划分 KV 缓存,研究发现轮次粒度的 Attention 分布存在两个重要规律。
▼ 提出 Round Attention inference pipeline :基于发现的两个规律提出 Round Attention ,将稀疏性从 Token 级提升至块级,选取最相关的块参与 attention 计算,减少 attention 计算耗时,并将不相关的块 offload 到CPU内存节省显存占用。该 pipeline 在保持推理精度的情况下,减少了推理耗时,降低了显存占用。
02 核心创新:轮次块稀疏性的三大优势
▼ 自然边界的语义完整性
问题洞察:多轮对话中,用户意图常以轮次为单位呈现(如“推荐餐厅”→“询问人均消费”→“确认地址”)。
解决方案:Round Attention 将 KV 缓存按轮次(对)切分为独立块,每个块完整包含一轮对话的提问与回答,确保模型在计算注意力时能直接关联完整语义单元。
▼ 分水岭层的注意力稳定性
关键发现:通过分析 SharedGPT 数据集,发现主流开源模型(如 Qwen2.5B )在特定“分水岭层”后,各层对历史轮次的注意力分布高度相似,且同一轮内问题与答案的注意力模式一致。
技术价值:仅需在分水岭层一次性筛选 Top-K 相关轮次,即可覆盖后续所有层的计算需求,相比其他工作逐层动态路由,有效减少 Top-K 计算开销。
▼ 端到端的存储与传输优化
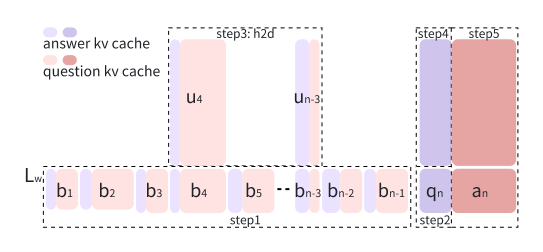
存储设计:将每轮 KV 缓存按分水岭层拆分为下层块( b_m )与上层块( u_m ),以轮次为单位整体存储于 CPU 内存,减少 GPU 内存占用。
传输效率:相比其他 kv cache offload 工作以 Token 级细粒度传输, Round Attention 以轮次为单位批量搬运 KV 缓存,单次 H2D 操作即可完成,降低 H2D 操作带来的延迟。
03 效果
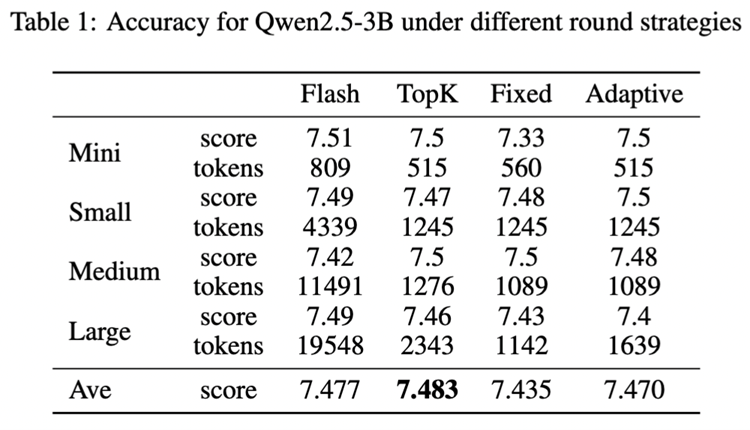
端到端延迟低于现在主流的 Flash Attention 推理引擎, kv-cache 显存占用节省 55% 到 82% ,并且在主观评测和客观评测两个数据集上模型推理准确率基本未受影响。
04 未来展望:开源协作与技术融合
摩尔线程 Round Attention 期待与开源社区深度协同,继续探索稀疏注意力可能的优化工作,共同攻克 LLM 落地中的效率与成本难题。该论文已发布在 arXiv :





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000